
Troubleshooting Repository Deadlocks

With Resilient Filesystem (ReFS) integration into Veeam Availability Suite 9.5 a whole bunch of features was integrated. One of the biggest advantages is ‚Fast Cloning Technology‘ which enables synthetic full backups by merely creating pointers to already existing datablocks on the repository.
In a small scale environment I had a hardware repository server (Win 2016) with an iSCSI Volume as repository (ReFS, 64k) as primary backup target. This constellation worked like a Swiss watch. Daily backups ran for months without any trouble. Fast cloning technology enabled weekly synthetic full backups with minimal consumption of extra space.
Recently I’ve added another iSCSI Volume (ReFS, 64k) to be used as repository for backup copies. That’s when the fun began…
I’ve scheduled backup copies on weekends to the secondary storage. An initial full backup was copied on schedule without problems. But one week later I got error messages by the Veeam Server (VM), reporting errors as it was unable to reach it’s repository. I’ve checked the environment and realized that the repository server wasn’t responding. Although I could ping the server, it was unmanageable. No RDP, no remote management console, not even a remote shutdown worked.
I had to switch the repo server off the hard way. After reboot it recovered and worked well throughout the week. I’ve checked the logs, but found nothing suspicious that could explain the deadlock.
On the next weekend all backup jobs failed again. Same procedure. Repository-Server unresponsive. Yet another hard reboot.
This time I didn’t believe in an accident. There must be a reason why the repository server goes berserk once the backup copy kicks in. After some research I’ve found a couple of forum posts with similar problems and also information by Microsoft that make me frown:
ReFS is supported with Storage Spaces, Storage Spaces Direct, and non-removable direct attached drives. ReFS is not supported with hardware virtualized storage such as SANs or RAID controllers in non-passthrough mode. USB drives are also not supported.
I read it over and over again. That means you’re not supposed to format a volume with ReFS as long as it is located on a SAN/NAS device. While reading deeper into the subject, I found out that this sentence might be limited to shared SAN storage. It seems to be related with RAID controllers that do not interpret the flush command correctly. But it doesn’t make a difference whether that RAID controller is locally in the host or on a remote storage device. It’s also irrelevant of the filesystem. This behavior can happen with ReFS or NTFS. There is a posting by Anton Gostev in the Veeam Forum, which clarifies the matter.
Possible explanations
Issue with iSCSI and ReFS
Possible, but not very likely (see above). There is another iSCSI Volume mounted to the same repository server. It’s formatted with ReFS too (64k blocksize) and it runs flawlessly.
Test: Format secondary target with NTFS (64k), repeat and observe.
As expected, reformatting the repository with NTFS (64k) did not remediate the situation.
Fun fact: Veeam recommends ReFS every time you try to modify the NTFS volume. 🙂
Target performance
Both storage systems have different hardware specs. The one behind primary repository is a modern system (Core i3 Dualcore 3.6 GHz with 8 GB RAM) and the one behind secondary storage is an older Atom (Dualcore 2.13 GHz, 1 GB RAM). Maybe the target storage becomes overloaded during backup copy.
I know, NAS devices are not the best choice as backup repositories. Of course a full blown storage with redundant controllers, SAS/Flash drives and sophisticated software is better. But many Veeam customers do not have an enterprise budget for backup infrastructure – unfortunately.
Test: Monitor resources during backup copy.
Result: There have been no resource shortages on the storage system. Neither memory, nor CPU, nor network. Disk latency was acceptable for a NAS device.
Limited resources on repository server
As it is a small scale environment, the repository server has limited resources. According to Veeam System Requirements, there should be at least 4 GB RAM plus 2 GB for every concurrent job. In this particular environment there is only a single task at a given time, the memory resource on the repository host (4 cores, 8 GB) should be sufficient. BUT… Veeam Backup creates a separate task for every disk of every VM to be processed. The repository allows 4 concurrent tasks (default value for 4 physical CPU cores). But that will overload the memory capacity of the repository. We’d need 8 GB alone to sustain the 4 tasks and there’ll be nothing left for the system.
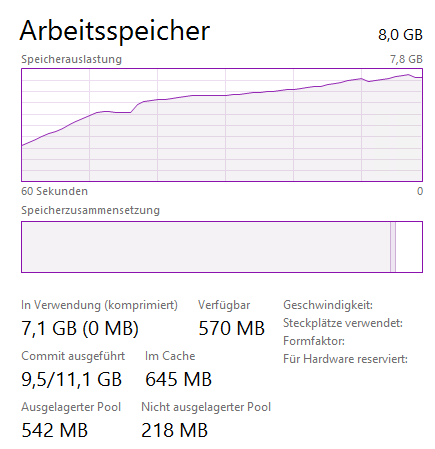
As you can see in the performance chart, memory is almost fully claimed.
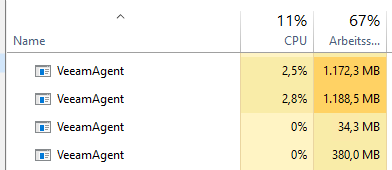
Veeam fired up 4 VeeamAgents for the backup copy job. One for each task. Luckily they had to handle just a small increment (copy test) and did not claim all memory resources. During a regular backup copy on weekends the situation is different. There are lots of changes to process and it is very likely that the 4 Agents took all the resources necessary to do their job and left almost nothing for the OS.
In this case the best advice would be to reduce the repository’s number of concurrent jobs to 2. That should leave enough headroom for the system.
Conclusion
Check hardware resources when creating new jobs.
It is a no-brainer on backup infrastructures with plenty of RAM and CPU. There you can just fire and forget. But the true challenge is in small scale environments with limited resources (due to limited budget). A couple of little adjustments can make a big difference.