
Dieser Artikel geht zurück auf Fragen, die immer wieder von meinen Studenten in vSAN-Kursen gestellt werden. Das Thema Striping klingt zunächst sehr einfach, aber es stellt sich als durchaus komplex heraus, sobald man von den einfachen Standardbeispielen abweicht. Wir beleuchten das Striping Verhalten von vSAN-Objekten bei Spiegelung, Erasure-Coding und bei großen Objekten. Wir zeigen auch das unterschiedliche Striping Verhalten vor der Version vSAN 7 Update 1 und danach.
Was ist Striping?
Striping bezeichnet ganz allgemein eine Technik, bei der logisch sequentielle Daten derart segmentiert werden sodass aufeinanderfolgende Segmente auf verschiedenen physischen Speichergeräten abgelegt werden. Striping schafft keine Redundanz. Das Gegenteil ist der Fall. Im klassischen Storage bereich wird Striping auch als RAID 0 beszeichnet (Merkhilfe: RAID 0 -> null Sicherheit). Durch die Verteilung der Segmente auf mehrere Geräte, auf die parallel zugegriffen werden kann, wird der Gesamtdatendurchsatz erhöht und die Latenz reduziert.
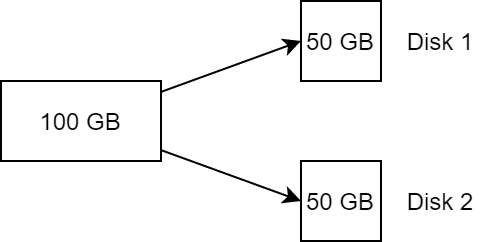
Die Stripe-Size oder Stripe Width bezeichnet dabei die Anzahl der Segmente, in die ein Objekt aufgeteilt wird.
Bei einer Stripe Width von 2 wird ein Objekt von beispielsweise 100 GB in zwei Komponenten zu je 50 GB segmentiert und auf zwei Datenträger verteilt. Dies entspricht einem RAID 0.
SPBM und Striping
VMware vSAN bietet die Flexibilität von Storage Policies, die pro Objekt definiert werden können. Nicht der Datenspeicher definiert die Eigenschaften wie z.B. Fehlertoleranz oder Stripe Size, sondern die Policy, welche am Objekt hängt. Man nennt dies Storage Policy Based Management (SPBM).
Zwei wichtige Eigenschaften, die über eine vSAN Storage Policy definiert werden können sind Fehlertoleranz (Failures to Tolerate, FTT) und Stripe Width (Number of disk stripes per object). Die Fehlertoleranz definiert die Anzahl der Kopien eines Objektes, die über unabhängige Fault Domains verteilt werden müssen. Stripe Width hat nichts mit Fehlertoleranz zu tun, sondern dient der Erhöhung des Datendurchsatzes durch Verteilung der Objekte als mehrere Komponenten über mehrere physische Datenträger (Disks).
Die Anzahl unserer Objekte im vSAN Cluster ergibt sich also aus dem Produkt der Kopien und der Anzahl der Stripe-Segmente. Ein 100 GB Objekt mit einer Policy von RAID1, FTT=1 und SW=2 resultiert somit in 2 Replikaten mit je zwei Komponenten (Stripe Segmente).
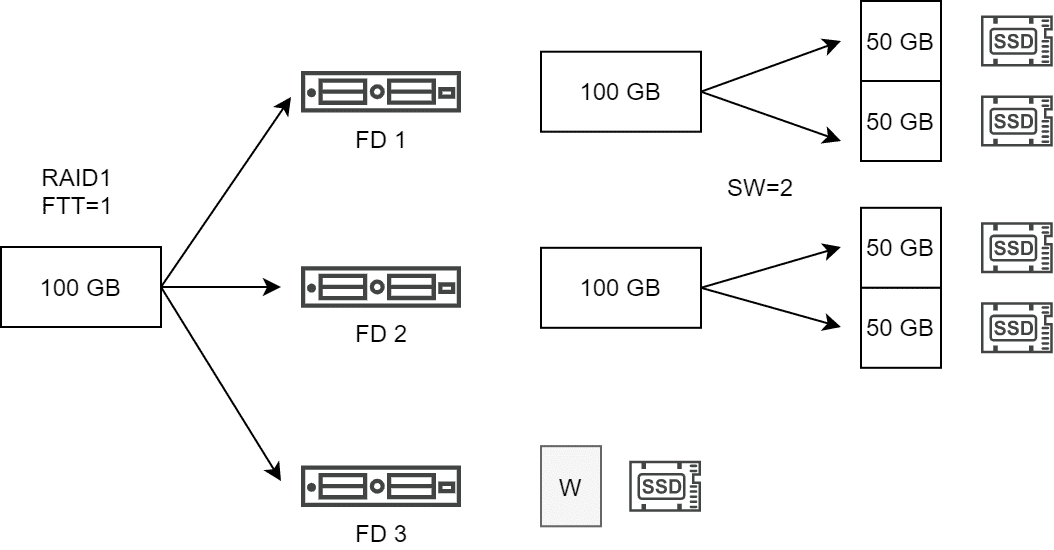
Der vSAN Host versucht, die Stripe-Komponenten auf unterschiedliche Diskgruppen zu platzieren. Ist dies nicht möglich, so werden unterschiedliche Disk Devices innerhalb einer Diskgruppe verwendet.
Wie ist das bei Erasure Coding?
Erasure Coding zerlegt Informationen in einzelne Stücke und erweitert sie mit Redundanzinformation in Form von Prüfsummen (Parity). Diese werden an physikalisch unterschiedlichen Orten in einem Speichersystem abgelegt.
Erasure Coding (EC) steht nur in All-Flash (AF) Clustern zur Verfügung. Es kann wahlweise als RAID5 (FTT=1) oder RAID6 (FTT=2) konfiguriert werden. Dafür werden bei RAID5 vier Komponenten bzw. 6 Komponenten bei RAID6 erzeugt.
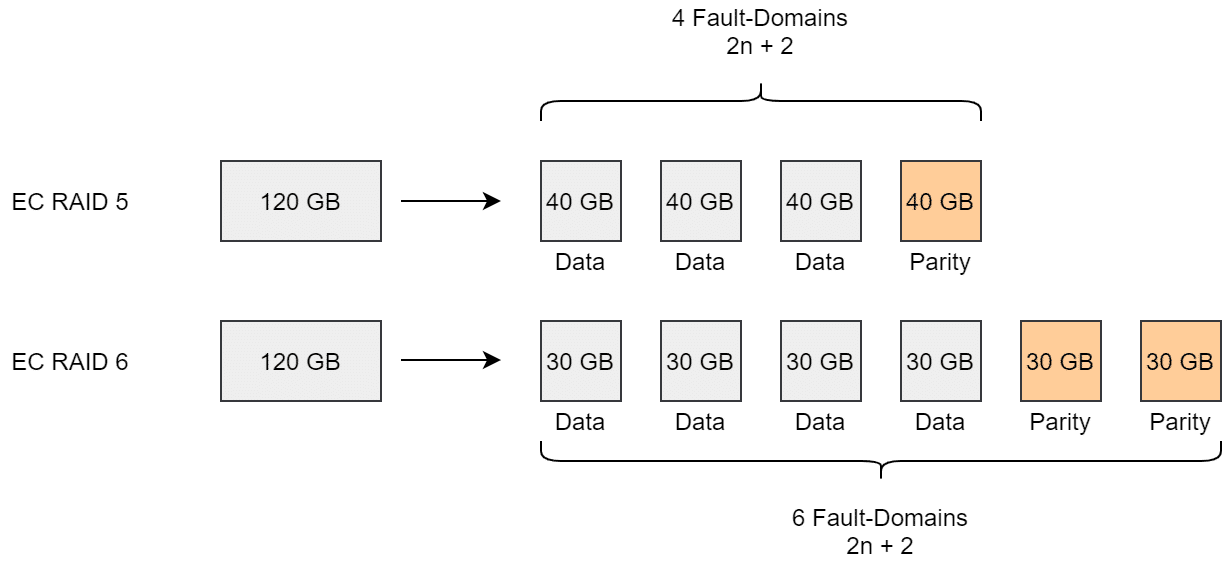
Betrachten wir die Stripe Width (SW) bei Erasure Coding, so müssen wir das Verhalten vor vSAN v7 Update1 und ab vSAN v7 Update 1 unterscheiden.
Vor vSAN7 U1
Ein 120 GB Objekt mit RAID5 und SW=4 muss über vier Fault Domains (FD) verteilt werden. Jede der Komponenten wurde in 4 weitere Komponenten zerteilt und auf unterschiedlichen Datenträgern abgelegt.
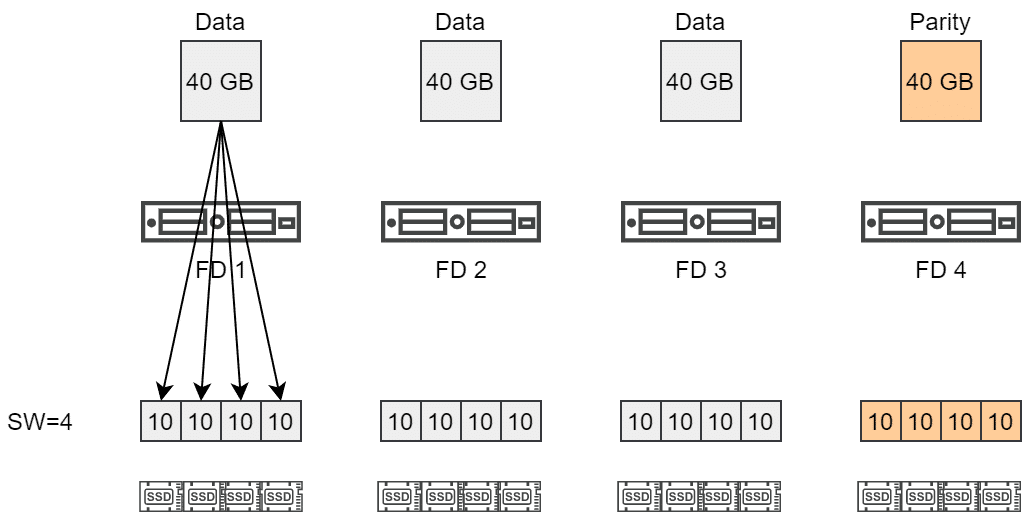
Dieses Verhalten führte zu einer starken Aufteilung der Komponenten, obwohl alleine schon durch die RAID5 Policy ein Striping über 4 Komponenten erreicht wurde, die zugleich auch über 4 Fault Domains verteilt sind.
Seit vSAN7 U1
Mit vSAN7 U1 änderte sich dieses Verhalten. Die Stipe Width definiert nun die Mindestanzahl an Komponenten. Erasure Coding RAID5 verteilt ein Objekt automatisch über 4 Hosts (Fault Domains, FD). Somit ist sie Vorgabe einer SW von 1, 2, 3 oder 4 bereits erfüllt.
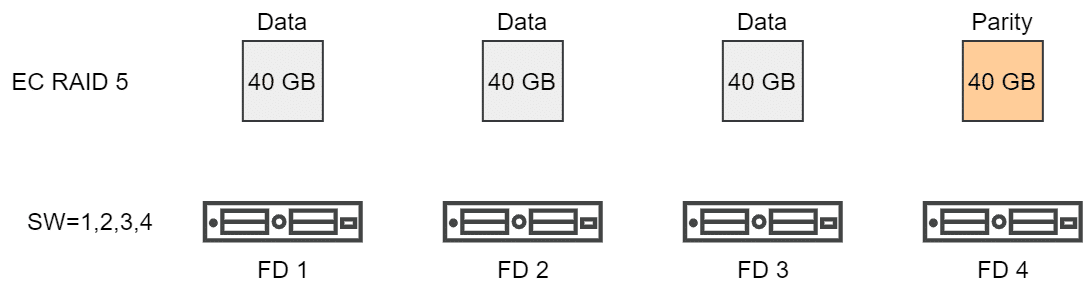
Erst wenn eine SW von größer 4 gefordert wird, werden weitere Stripes gebildet. Dies gilt dann für SW=5, 6, 7 oder 8.
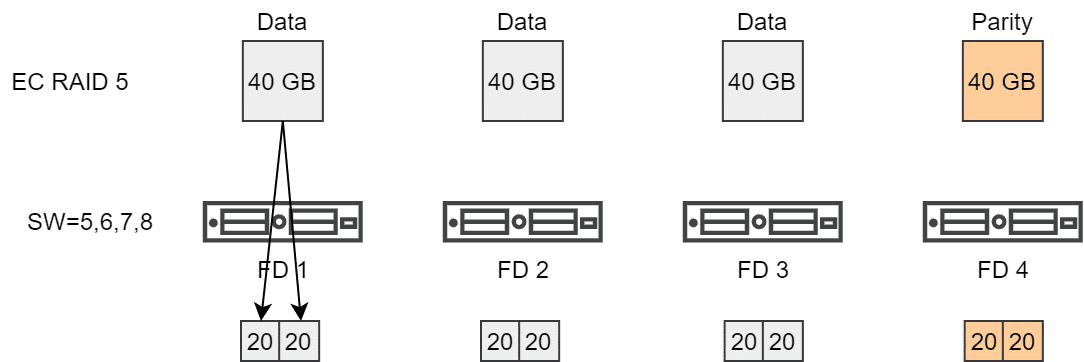
Stripes bei Erasure Coding RAID5 Policies müssen also in Vielfachen von 4 angegeben werden um wirksam zu sein. Analog müssen die Stripes bei RAID6 in Vielfachen von 6 angegeben werden, um eine Segmentierung zu erreichen.
Ein Objekt mit einer EC RAID6 Policy und SW=12 würde über 6 Hosts verteilt werden, mit je 2 Komponenten pro Host (=FD). Also insgesamt 12 Komponenten im Gegensatz zu 6×12 Komponenten vor vSAN7 Update1.
Große Objekte
Unabhängig von der gewählten Stripe Size, spaltet vSAN automatisch Objekte von mehr als 255 GB in mehrere Komponenten auf.

Im obigen Beispiel erfolgt ein erzwungener Split des Objektes bei 255 GB in zwei Komponenten. Die beiden Komponenten werden dann als RAID5 über vier Fault Domains (hier Hosts) verteilt. Auch hier liefert eine Stripe Width von 1, 2, 3 oder 4 das selbe Ergebnis.
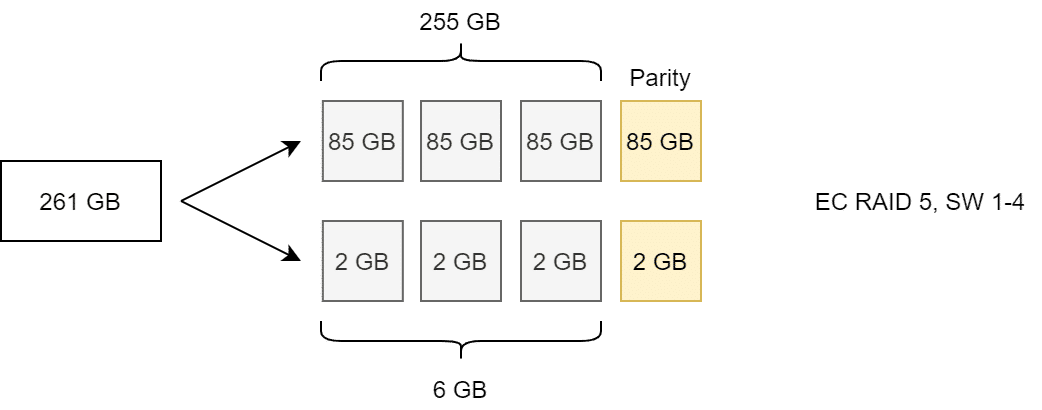
Erst ab SW=5 verdoppelt sich die Anzahl der Komponenten. (Beispiel mit 261 GB für leichtere Berechnung)
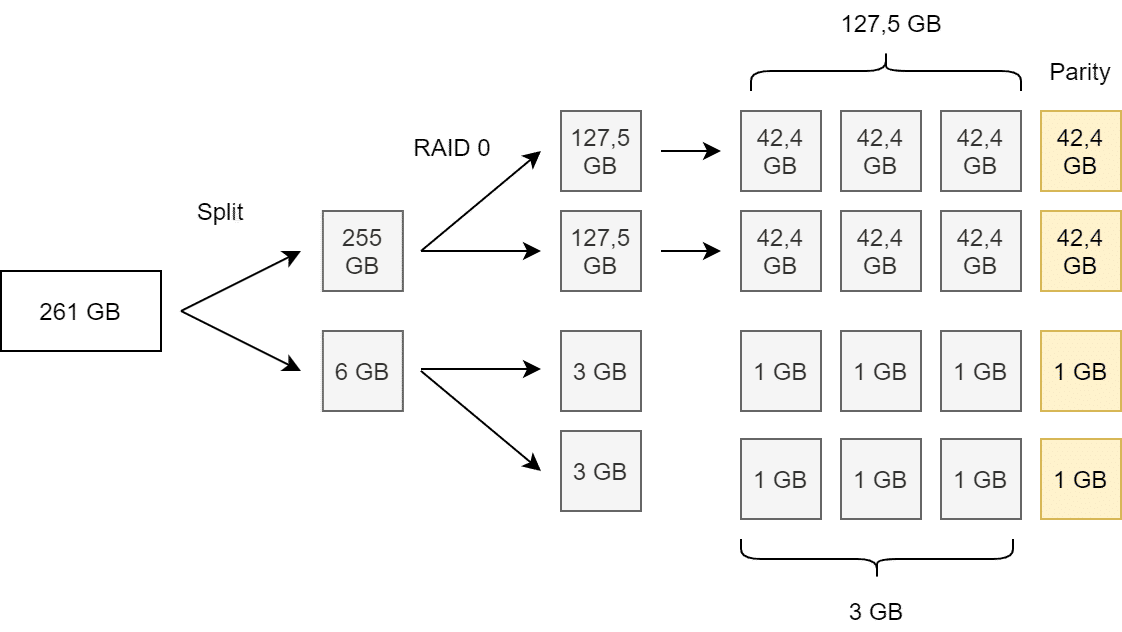
Zu beachten: Die Aufteilung großer Objekte ist eine asymmetrische Spaltung (255 GB plus 6 GB), während Striping zu einer symmetrischen Komponentenaufteilung führt (vgl. Abbildung oben).
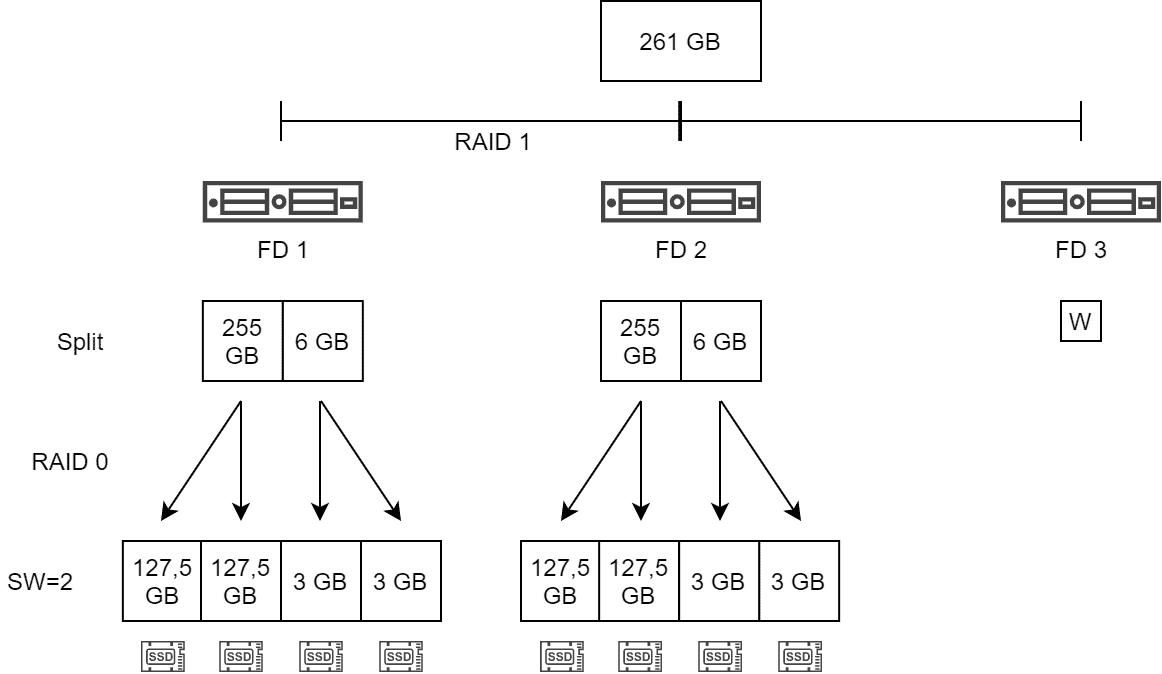
Mirror Policy und große Objekte
Bei Verwendung einer Mirror Policy (RAID 1) auf großen Objekten von mehr als 255 GB und einer Stripe Width von 2 sieht das Bild wie unten dargestellt aus. Zunächst erfolgt der obligatorische Split des großen Objekts, danach das Striping (RAID 0). Zur Schaffung von Redundanz wird ein RAID 1 aller Komponenten über mehrere Fault Domains gebildet (hier 2 Hosts plus Witness).
Den Objekten auf der Spur
Im vSphere Client kann man die VM selektieren und dann unter Monitor > Physical Disk Placement die Organisation der Komponenten darstellen. Wir erhalten jedoch keine Information zur Größe der Komponenten. Hier hilft uns die esxcli weiter.
esxcli vsan debug object list
Dieser Befehl liefert alle Cluster-Objekte mit Details wie z.B. Object UUID, Owner, Größe, Policy, Belegung, oder Votes zurück. Das kann sehr schnell sehr unübersichtlich werden. Es empfiehlt sich daher die Ausgabe in eine Datei.
esxcli vsan debug object list > /tmp/objects
Das erzeugte Textfile kann man beispielsweise über SCP vom ESX-Host auf eine Windows Workstation laden und anschließend mit einem Editor der Wahl (z.B. Notepad++) durchsuchen.
Bitte die unterschiedlichen Pfadseparatoren in ESXi und Windows beachten.
scp root@esx01.lab.local:/tmp/objects c:\temp\objects
Die Abbildung unten zeigt einen kleinen Auszug aus der Objektliste. Das Objekt (vDisk) hat eine Größe von 260 GB. Es wird aufgeteilt in 255 GB und 5 GB. Gemäß der RAID5 Policy ergeben sich daraus 3×85 GB = 255 GB für Daten zuzüglich 85 GB Parity und 3×1.67 GB = 5 GB für Daten zuzüglich 1.67 GB Parity (rote Markierungen).
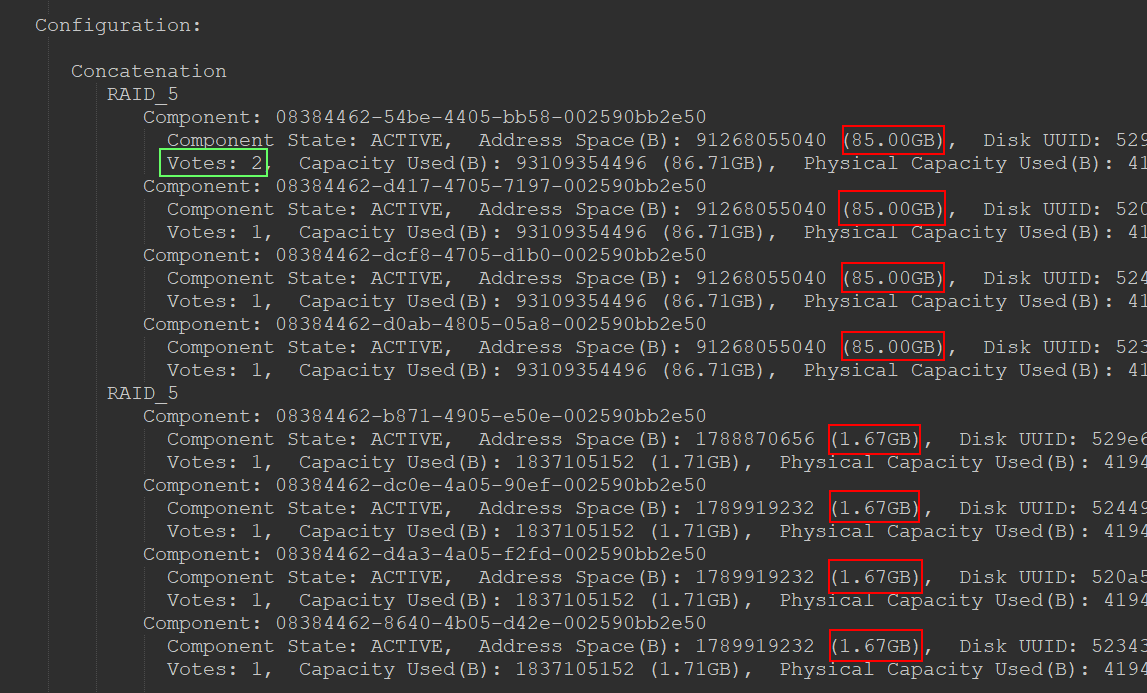
Eine kurze Randnotiz ist hier noch anzumerken. Eine der Komponenten verfügt über zwei Votes (grüner Kasten). Dies ist bei Erasure Coding Policies immer der Fall, da die Summe der Votes keine gerade Zahl sein darf, denn zum Quorum sind immer mehr als 50% aller Votes erforderlich. Genau genommen kann es bei Erasure Coding nicht zu einem Split-Brain Szenario kommen. Im Gegensatz zu RAID1 haben wir hier keine vollständigen Kopien, sondern nur Teilsegmente. Eine 2+2 Aufteilung resultiert für beide Seiten in einem unvollständigen und somit nicht erreichbaren Objekt. Dennoch erhält eines der Objekte 2 Votes, um eine ungerade Anzahl zu garantieren. So will es das Gesetz! 😉