
Wenn es darum geht, virtuelle Maschinen auf einen Datenspeicher zu platzieren, so steht man vor einem Dilemma: Natürlich möchte man allen Arbeitslasten die bestmögliche Leistung des Datenspeichers zukommen lassen. Dies ist aber aus finanziellen Gründen nicht wirtschaftlich und wie wir später sehen werden auch nicht notwendig. Die Frage lautet immer:
Volumen oder IOPS ?
Flash Speicher bietet zwar ausgezeichnete Zugriffszeiten, ist dafür aber verhältnismäßig teuer in der Anschaffung. Im Gegensatz dazu bieten SATA Festplatten ein sehr gutes Preis pro GB Verhältnis, aber sie können hohe IO Anforderungen nicht bedienen.
Der Königsweg liegt in einem Mix aus mehreren Speicherklassen. SSD/Flash für sehr schnelle Zugriffe, SAS Festplatten für mittlere bis schnelle Zugriffe und SATA Festplatten für viel Volumen bei wenig Leistungsanforderung.
Präsentiert man diese Speicherklassen diskret an die (ESX-) Server, so steht man vor dem nächsten Problem. Welche VM hat welche Anforderungen? Eine Datenbankserver-VM muss schnell sein, aber gilt dies für die gesamte vDisk, oder haben nur kleine Bereiche hohe Zugriffe? Gibt es auf einem Fileserver vielleicht auch Bereiche die sehr stark frequentiert werden? Dies im Vorfeld zu entscheiden ist sehr schwierig. Besser wäre es, diese Entscheidung nicht auf vDisk Ebene zu treffen, sondern viel granulärer auf Blockebene. „Heisse“ Blöcke gehen auf schnellen Speicher, „kalte“ dagegen auf langsamen Volumenspeicher. Dummerweise lässt sich dies seitens der Serversysteme (z.B. ESX, Hyper-V etc.) nicht steuern.
Storage Tiering
Hier hilft eine Technik in SANSymphony-V von DataCore mit dem Namen „Automatic Storage Tiering“ (AST). Das Prinzip ist clever: Alle Datenspeicherklassen (Flash, SAS, SATA) werden von DataCore in einen Pool geworfen und vom Administrator mit einem Geschwindigkeits-Index (Tier) versehen. Aus diesem Pool werden Volumes gebildet und dem ESX Server präsentiert. D.h. der ESX Server hat keinerlei Kenntnis, um welchen Speichertyp es sich beim präsentierten Volume handelt. Die Enscheidung der Platzierung fällt alleine auf Seite des Datacore Clusters. Dafür wird der Pool in kleine Bereiche sog. „Storage Allocation Units“ (SAU) von 128 MB Größe unterteilt. Diese wandern je nach IO von langsamen zu schnellen Speichern, oder auch wieder zurück.
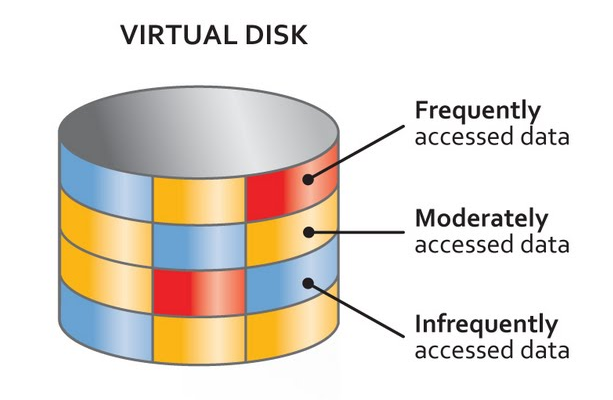
Im Bild links sehen wir ein schematisches Bild einer vDisk mit heissen (rot), moderaten (gelb) und kalten Bereichen (blau). Wichtig ist, daß die roten Bereiche auch wirklich auf den physischen Datenträger zu liegen kommen, die die Anforderungen leisten können. Im Umkehrschluss dürfen auch nur solche Blöcke auf Premium Speicher landen, die die die Leistung auch benötigen, also nicht kalt sind.
In der Praxis
Ich möchte hier anhand einer realen Umgebung zeigen, wie dies funktioniert.
Das System besteht aus zwei identischen Datacore Servern mit jeweils 32 GB Cache Speicher und je einer über FibreChannel (8G) angebundenen Storage. Diese ist mit SAS (10k) Disks bestückt welche zu RAID 5 und RAID 10 verbunden sind. Als Top-Tier fungiert Flash Speicher. Dieser wurde aber nicht in Form von SSD im Storage-System realisiert, denn bei schnellen SSD gibt es zwei Flaschenhälse. Der Festplattencontroller und die 8G FC Anbindung der Storage. Die FC Verbindung (8G) schafft rechnerisch eine Übertragungsrate von etwa 800 MB/s(*). Das ist schnell genug für herkömmliche SAS Platten, aber unter Umständen zu langsam für Solid-State/Flash Speicher.
(*) Das ist kein Rechenfehler. 8 GBit/s entsprechen zwar 1 GByte/s, aber durch das Übertragungsprotokoll 8B10B werden nur 80% der Bandbreite für Daten und der Rest für Prüfsummen genutzt.
Zur Verbeidung des Flaschenhalses entschieden wir uns für eine wesentlich schnellere Art der Anbindung: PCi Express . PCi Express Karten können je nach Bauart mit mehreren Lanes zu je 500 MB/s angefahren werden. Das im Beispiel verwendete ioDrive2 der Firma Fusion-io verwendet 4 Lanes und hat eine Speicherkapazität von 360 GB. Diese Speicherkapazität erscheint nicht besonders groß, aber durch die Verwendung von AST wird sicher gestellt, dass nur die aktivsten (heissen) Blöcke auf dem Flash-Speicher zu liegen kommen. Der Rest liegt auf SAS RAID10 bzw. SAS RAID5.
. PCi Express Karten können je nach Bauart mit mehreren Lanes zu je 500 MB/s angefahren werden. Das im Beispiel verwendete ioDrive2 der Firma Fusion-io verwendet 4 Lanes und hat eine Speicherkapazität von 360 GB. Diese Speicherkapazität erscheint nicht besonders groß, aber durch die Verwendung von AST wird sicher gestellt, dass nur die aktivsten (heissen) Blöcke auf dem Flash-Speicher zu liegen kommen. Der Rest liegt auf SAS RAID10 bzw. SAS RAID5.
Hier eine Abbildung der PCi-Express Karte. Da es sich hier um einen potenziellen singulären Fehlerpunkt handelt (SPOF), müssen beide Datacore Server mit einer solchen Karte ausgestattet werden. Alle präsentierten Volumes werden synchron gespiegelt. Bei Ausfall eines Bauteils, eines Datacore-Servers, oder eines RAID Sets auf der Storage übernimmt der Partnerknoten volltransparent.

Auto Tiering bei der Arbeit
Das Folgende Diagramm zeigt die Verteilung der Blöcke (SAU) auf die pysischen Speicher. Tier1 mit Fusio-io, Tier2 mit SAS RAID10 und Tier3 mit SAS RAID5. Blaue Bereiche sind belegt, weisse frei. Dunkelblaue Säuen bezeichnen heisse Bereiche. Je höher diese Säule, desto mehr IO ist auf diesem Block.
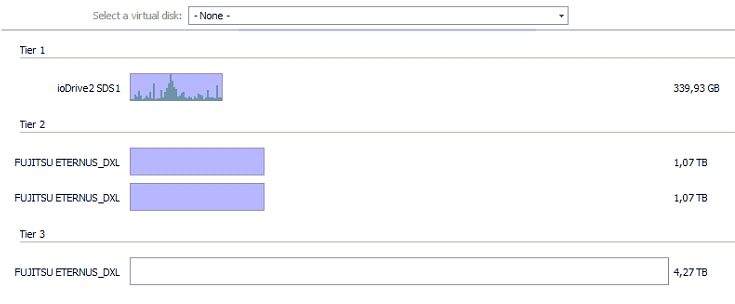 Es fällt zunächst auf, daß der teure Flash Speicher und das RAID10 zu 100% genutzt wird. Es gibt keinen Verschnitt oder freie Reserve-Bereiche. Heisse Blöcke konzentrieren sich auf dem Flash Speicher und genau das ist seine Aufgabe. Auf der korrespondierenden Spiegelseite sieht das Bild fast identisch aus, daher wird hier auf eine weitere Abbildung verzichtet.
Es fällt zunächst auf, daß der teure Flash Speicher und das RAID10 zu 100% genutzt wird. Es gibt keinen Verschnitt oder freie Reserve-Bereiche. Heisse Blöcke konzentrieren sich auf dem Flash Speicher und genau das ist seine Aufgabe. Auf der korrespondierenden Spiegelseite sieht das Bild fast identisch aus, daher wird hier auf eine weitere Abbildung verzichtet.
Latenzen
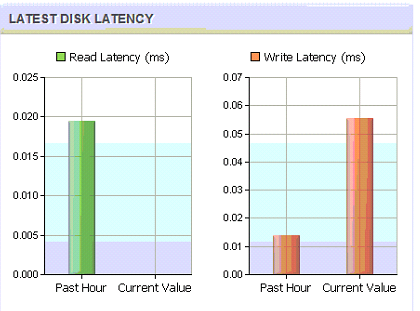
Das Thema Latenzen – also die Wartezeit der ESX Server bis zum Storagezugriff – ist seit der Einführung des Datacore Clusters keines mehr. Betrachtet man bei herkömmlichen Storage Systemen Latenzen von 10-20 ms als einen guten Wert, so sind diese aktuell um den Faktor 20-100 geringer. Sowohl Lese- als auch Schreiblatenzen liegen deutlich unter 1 ms (!). Im Bild links eines von derzeit drei Datacore-Volumes welches den ESX Servern Präsentiert wird. Diese Verbesserung ist vor allem dem großen Cache des Datacore Servers zu verdanken. Dabei wird nur die erste Anfrage vom Storage Cluster bedient. Alle weiteren kommen aus dem Cache.
Links
- Fusion-io – Website
- Datcore – Auto Tiering