
Was ist beacon probing?
In meinem kürzlich veröffentlichten Blog-Artikel „ESX physische Uplinks gegen Pfadausfall sichern„, habe ich „Link State Tracking “ diskutiert. Eine Methode mit der man den LAN Datenverkehr gegen physische Ausfälle härten kann. Heute möchte ich eine andere Methode der Ausfallsicherung beschreiben, mit der man Uplinks identifizieren kann, die entweder fehlerhaft oder isoliert sind.
Gründe für solche Fehler können zum Beispiel Treiber / Firmware Unverträglichkeiten sein, oder schlicht ein defektes Kabel auf dem Weg zum Coreswitch.
Beacon probing
Beacon probing ist ein Mechanismus, bei welchem der ESX Host im Sekundenabstand Pakete über alle Uplink Ports sendet und kontrolliert, auf welchen anderen Uplink Ports diese empfangen werden. Beacon bedeutet „Leuchtfeuer“ und ist eine treffende Bezeichnung. Jeder Uplink sendet Leuchtfeuer aus und empfängt die Signale der anderen Uplinks.
![]()
Betrachten wir im obigen Bild den Uplink vmnic0. So lange dieser Beacons der beiden Uplinks vmnic1 und vmnic2 empfängt, hat der Host zwei wichtige Informationen:
- vmnic0 ist verbunden und funktional
- vmnic1 und vmnic2 sind ebenfalls verbunden und funktional
Diese Methode hat den Vorteil, daß eine Störung im Pfad entdeckt werden kann, auch wenn der direkt angeschlossene Switch Verbindung zum Uplink hat. Auch eine Port Fehlfunktion kann ermittelt werden, denn dieser Port wird weder Signale senden, noch welche empfangen. VMs, die an den Uplink gebunden sind können dann auf einen alternativen Uplink umschalten.
![]()
Hier haben wir eine Störung zwischen Switch1 und dem Coreswitch. Der Linkststus von vmnic1 ist im Zustand „up“, denn es besteht eine aktive Verbindung zu Switch1. Die Fehlererkennung „Link State only“ würde diesen Uplink als funktional deklarieren. Beacon probing erkennt jedoch das weiter außerhalb gelagerte Problem irgendwo im Pfad von vmnic1. VMs auf der Portgruppe PG1 schalten um auf vmnic2.
Fallstricke bei der Verwendung von beacon probing
Diese Methode hat einige Implikationen, die es zu beachten gilt.
Verwende mehr als zwei Uplinks pro vSwitch
Um ein so genanntes „split brain“ Szenario zu vermeiden, benötigt man mindestens drei Uplinks pro vSwitch. Mit nur zwei Uplinks kann der Host unmöglich entscheiden, welcher der beiden Uplinks eine Störung hat. Keiner von beiden empfängt Beacons des anderen.
![]()
Uplinks mit unterschiedlichen Switches verbinden
Wenn man alle Uplinks auf einen Switch verbindet, führt man das Prinzip Beacon Probing ad absurdum, denn die Signale werden kurzgeschlossen. Auch wenn eine Störung im Pfad vorliegen sollte, werden die Beacons gesendet und emofangen und das Problem bleibt unentdeckt.
![]()
Falsch-negative und falsch-positive Resultate
Verbindet man mehr als einen Uplink mit dem selben Switch und verwendet Beacon Probing als Fehlererkennung, kann man paradoxe Ergebnisse erhalten. Ein funktionaler Pfad wird als fehlerhaft deklariert und gestörte Pfade als funktional.
Schauen wir uns das Bild unten an. Switch1 hat den Kontakt zum Coreswitch verloren, aber vmnic1 und vmnic2 tauschen weiterhin erfolgreich Beacons aus. Der Uplink vmnic0 ist der letzte verbleibende intakte Pfad, jedoch empfängt er keine Beacon von vmnic1 und vmnic2 mehr. Diese empfangen auch keine Beacons von vmnic0, da sie selbst isoliert sind. Aufgrund dieser Ergebnisse wird der Host entscheiden, dass vmnic0 gestört ist und ein Failover der Portgruppe PG0 zu vmnic1, oder vmnic2 einleiten.
![]()
Die Kommunikation des vSwitches mit der Außenwelt wird daraufhin gekappt, obwohl es noch einen funktionierenden Pfad über vmnic0 gäbe. In einem solchen Fall wäre Link State Tracking die Methode der Wahl.
Was ist mit Switch-Clustern?
Was passiert, wenn wir unsere Uplinks mit verclusterten Switcheinheiten wie z.B. IRF verbinden?
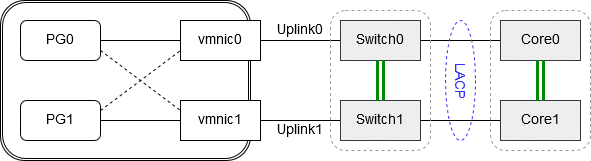
Da sich IRF Cluster wie eine logische Einheit verhalten, müssen wir sie so behandeln, als seien alle Uplinks zu einem einzigen Switch verbunden. Durch die hohe Pfadredundanz bei Switchclustern mit LACP Trunks genügt die Einstellung „link state only“.
Dinge, die man nicht tun sollte
Vorsicht ist geboten bei der Kombination von Fehlererkennung und Load-Balancing in vSwitches.
- Beacon Probing darf nicht in Kombination mit der Load-Balancing Richtlinie „Route based on IP Hash“ verwendet werden. -> vgl. KB 1017612
- Beacon Probing darf nicht mit Etherchannel Kanalbündelung eingesetzt werden. -> vgl. KB1012819