
vmnic Redundanz mit Link State Tracking / Smartlinks absichern
Ein vSphere Cluster sollte in jeder Hinsicht redundant ausgelegt sein. D.h. der Ausfall einer Komponente darf nicht zum Funktionsverlust führen. Wir bilden RAID Sets aus mehreren Disks, steuern Storage Einheiten über mehrere Controller, haben mehrere Pfade zur Storage, redundante LAN- und SAN-Switches und mehrere Uplinks pro Host ins physische Netzwerk.
VMware vSphere verwendet mehrere physische Uplinks, um daraus einen logischen NIC zu erstellen. Somit wird Redundanz gewährleistet. Besonders für Kenelports ist Redundanz besonders wichtig. Über diese wird das Management Network, vMotion, FT, iSCSI und Heartbeats abgewickelt.
Es gibt aber Szenarien, bei denen alle NICs eines ESX physischen Link haben und dennoch ein Pfadausfall auf dem Weg zum Core-Switch dazu führt, daß Pakete ins Nirvana gesendet werden.
Wir werden im folgenden Teil mehrere Architekturen anschauen und Methoden zeigen, um dies zu verhindern.
Das Problem
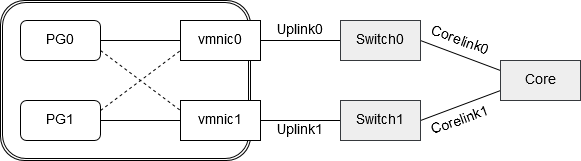
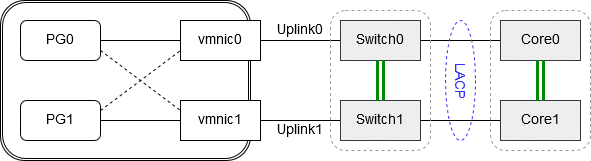
Portgruppe PG0 hat vmnic0 als aktiven Uplink zugeordnet und vmnic1 als Standby für den Fall, daß Uplink 0 ausfallen könnte. Portgruppe PG1 verhält sich genau umgekehrt. Sie hat vmnic1 als Uplink und vmnic0 als Standby, für den Fall daß Uplink1 ausfallen könnte. Vmnic0 und vmnic1 sind mit unterschiedlichen Switches verbunden (Switch0 und Switch1). Würde einer der Switches ausfallen, oder neu starten, so geht der Uplink in den Status „link down“ und die betroffene Portgruppe würde den alternativen vmnic verwenden. Soweit alles in Ordnung.
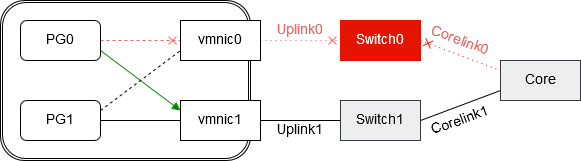
Was würde aber passieren, wenn Corelink0 ausfiele? Uplink0 wäre weiterhin im Status „link up“, denn es besteht eine aktive Verbindung zwischen vmnic0 und Switch0. Portgruppe PG0 würde deshalb weiterhin Pakete über vmnic0 zu Switch0 senden. Es gibt aus Sicht von Portgruppe PG0 keinen Grund, auf den Standby vmnic1 umzuschalten. Die Folge sind Pakete von Portgruppe PG0, die ihr Ziel nie erreichen und trotz definierter Standby-Verbindung wird diese nicht aktiviert.
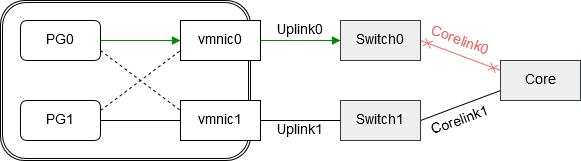
Lösung 1 – Link State Tracking / Smartlinks
Enterprise Switches haben ein Feature, das bei Cisco „Link State Tracking“ und bei HPE „Smart Links“ genannt wird. Hierbei werden Gruppen abhängiger Links gebildet. Fällt ein Link aus, so wird auch der Port des abhängigen Links aktiv ausgeschaltet.
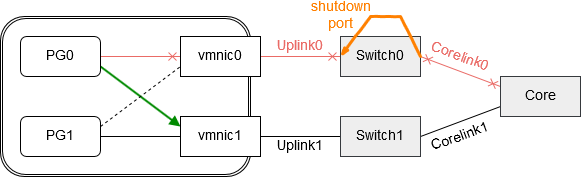
Für unsere Portgruppen entsteht nun eine neue Situation. Fällt Corelink0 aus, so schaltet Switch0 den korrespondierenden Port Richtung vmnic0 aktiv aus. Vmnic0 ist damit im Status „link down“ und Portgruppe PG0 kann jetzt auf den alternativen Pfad über vmnic1 umschalten.
Lösung 2 – Switch-Cluster
Wir verwenden in diesem Szenario keine singulären Switches auf dem Weg zum Core, sondern verclustern diese mit Hilfe der Technik Intelligent Resilient Framework (IRF) bei HPE/3Com bzw. Virtual Switching System bei Cisco.
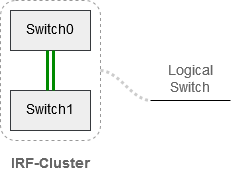
Switch0 und Switch1 werden mittels IRF zu einer logischen Einheit verclustert. Zwei Units, ein logischer Switch. Der Vorteil ist nun, daß Pakete zwischen den beiden Top-of-Rack (TOR) Switches ausgetauscht werden können, ohne daß wir dabei einen Loop bilden (kein Spanning Tree Protokoll nötig). Den Core-Switch verclustern wir auf die gleiche Weise. Von jeder Einheit des TOR Switches führen wir einen Uplink zu einer Einheit des Core-Switches. Damit auch hier kein Loop entsteht, werden beide Uplinks zum Core über einen LACP Trunk gebündelt. Es entsteht eine logische Verbindung aus mehreren physischen Uplinks.
Schauen wir unser vorheriges Szenario nochmals an: Wieder wird Corelink0 unterbrochen. Pakete von vmnic0 werde jedoch weiterhin zugestellt. Die Umleitung erfolgt im TOR Switch über den IRF-Link zu Core Unit1.
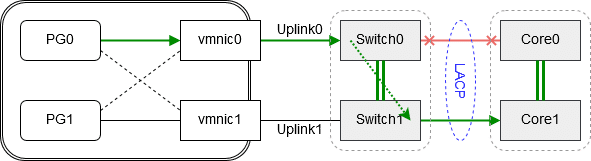
Info: Diese Architektur kommt gänzlich ohne Spanning Tree Protokoll (STP) aus und es finden damit auch keine Neuverhandlungen statt.