
Ensure vmnic uplink redundancy with Link State Tracking / Smart Links
A vSphere cluster is redundant in many aspects. The loss of one component may not lead to a loss of functionality. Therefore we are building RAID sets from multiple disk drives, have redundant controllers in our storages, have multiple paths, redundant LAN- and SAN-switches and multiple uplinks from a host to the physical network.
VMware vSphere uses multiple physical NICs to form a logical NIC in order to gain redundancy. This is crucial for kernelports, which are responsible for vMotion, Management Network, FT, iSCSI and Heartbeats.
But there are scenarios where all vmnics have physical uplink, but a path loss further downstream towards the core lets packets wander into a black hole.
We will now discuss some network architectures and how to work around the issue.
The Problem
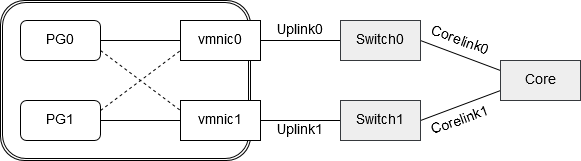
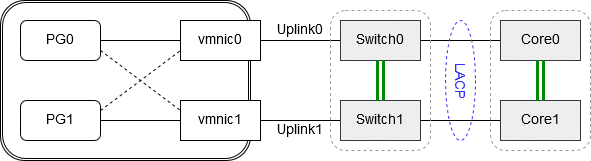
Portgroup PG0 has vmnic0 configured as active uplink and vmnic1 as standby in case vmnic0 loses connectivity. Portgroup PG1 is configured the other way round. It has vmnic1 as active uplink and vmnic0 as standby, in case link on vmnic1 might fail. Vmnic0 and vmnic1 are connected to independent switches (Switch0 and Switch1). If one of these switches fails or reboots the uplink will go into status “link down” and the affected portgroup would switch over to its alternate vmnic. So far so good.
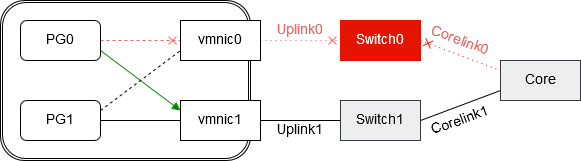
But what would happen, if Corelink0 would fail? Uplink0 still has a physical link to Switch0. Portgroup PG0 would go on sending packets over vmnic0 to Switch0. From PG0’s point of view there’s no reason to fail over to vmnic1. The result are lost packets. Despite of having a defined alternate uplink, PG0 would not fail over.
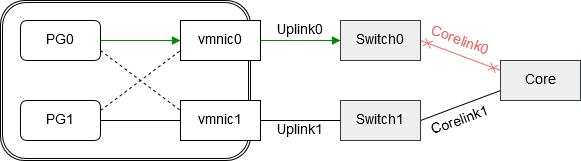
Solution 1 – Link State Tracking / Smartlinks
Enterprise class switches usually do have a feature named “Link State Tracking” (Cisco) or “Smart Links” (HPE). Groups of dependent links will form a “tracking” or “Smart” group. If one link in the group fails, the corresponding port of a dependent link in the group will be shut down.
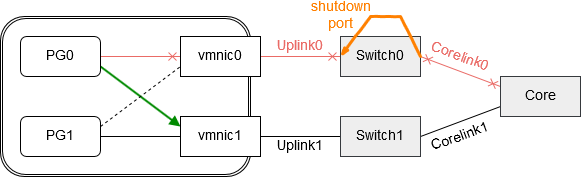
Now there’s a new situation for our portgroups. Let’s see what happens if Corelink0 fails. Switch0 will now shut down the corresponding port of Uplink0 and vmnic0 will go into status “link down”. This is good for PG0, because it can now fail over to its alternate path on vmnic1.
Solution 2 – Switch-Cluster
Instead of independent switches we will use clustered switches. This can be achieved by HPE’s Independent Resilient Framework (IRF), or Cisco’s Virtual Switching System.
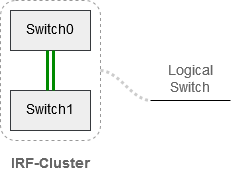
Both Top-of-Rack (TOR) switches Switch0 and Switch1 will be clustered to form a logical switch. Two units – one logical switch. Now we can exchange packets between units Switch0 and Switch1 without building a loop (no spanning tree protocol necessary). We do the same with our core switch by clustering two units into an IRF-Custer. Each TOR switch unit will be connected to one unit of the core cluster. In order not to build a loop, we will aggregate both links into a LACP trunk. We then have one logical link between ourTOR cluster and the core cluster.
Let’s repeat the scenario where Corelink0 fails. Packets from vmnic0 will not be lost. Redirection happens on the TOR switchcluster over its internal IRF-link. Packets from PG0 will go from vmnic0 to unit Switch0, to unit Switch1 to Core-Unit1.
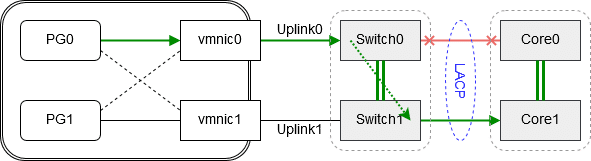
Note: There’s no need for spanning tree protocol (STP) in this architecture and there will be no poisonous root elections in the network.
[* Shield plugin marked this comment as “spam”. Reason: Human SPAM filter found “great post” in “comment_content” *]
Great post, thanks!
I think for Solution 1 scenario also the Beacon Probing network failure detection can help.
https://vswitchzero.com/2017/06/18/beacon-probing-deep-dive/
If you are looking for a way to verify your setup from host side, you can take a look at this script:
https://mycloudrevolution.com/2017/03/28/script-esxi-vmnic-uplink-details/
Thanks Markus
I apologize for the very late reply. It seems that a keyword has triggered my comment spam filter.
I haven’t cleaned up comments for a while. 😉 Shame on me.