I will be giving a presentation on the migration of a vSAN cluster at this year’s VMware Explore in Barcelona. This is not just about the technical implementation, but rather about the decision-making process. If plan A doesn’t work, you should have a plan B ready. Or – as in my practical example – a plan C and ultimately a plan D.
The easy way is not always the best and even a less attractive alternative can ultimately lead to success.
CODE1405BCN
The presentation is listed in the VMware Explore Content Catalog under the number 1405 .
Monday, November 4 – 15:00 CET.
I am delighted.
vSAN Cluster Live-Migration to new vCenter instanceIf you can’t make it to Barcelona but are still interested in the topic (spoiler alert!), you can find the full story here on my blog.
As part of my work as a trainer, I often come across questions on topics that are only covered in passing or not at all in the course. This series of articles provides trainee IT experts with tools for everyday use.
Intro – What are Diskgroups?
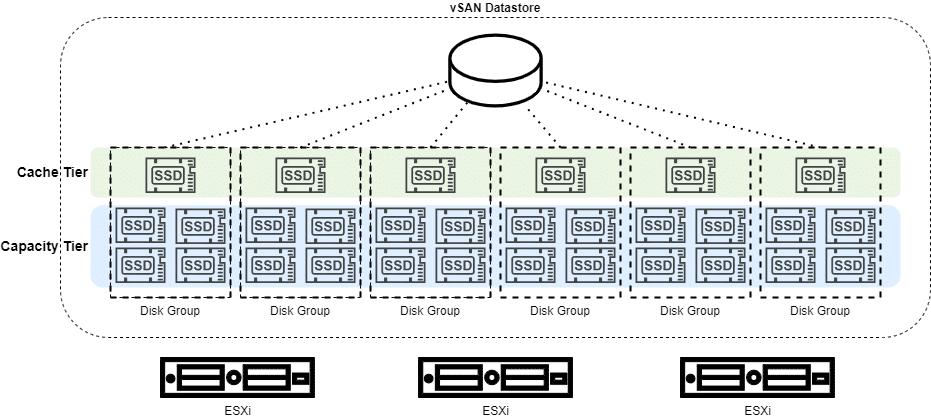
VMware vSAN OSA (original storage architecture) structures the vSAN datastore into disk groups (DG). Each vSAN node can contain up to 5 disk groups. Each of these disk groups consists of exactly one cache device (SSD) and at least one to a maximum of 7 capacity devices per group. These may be either magnetic disks or SSDs, but no combination of the two. We differentiate between cache tier and capacity tier.
Disk groups can be managed using the graphical user interface (GUI). However, there are situations where disk group management on the command line interface (CLI) is necessary or more appropriate.
UUID
Each disk device of a vSAN cluster (OSA) has a universally unique identifier (UUID).
We can list all devices of a vSAN node on the CLI with this command:
esxcli vsan storage list
The sheer amount of information may be a bit too much and we only want to display the lines containing the UUID.
esxcli vsan storage list | grep UUID
We receive a list of all disk devices in the vSAN node. We also receive the UUID of the disk group to which the device is assigned.
If you take a closer look at the output, you will notice that there are some devices whose UUID is identical to the UUID of the diskgroup. Is this a contradiction to the statement that the UUID is unique? No. These are cache devices. Each diskgroup in vSAN OSA consists of exactly one cache device. The disk group adopts the UUID of its cache device. In this way, we can quickly distinguish a cache device from a capacity device.
With the release of vSphere 7.0 Update 1, vSphere Cluster Services VMs (vCLS) appeared in vSphere clusters for the first time. This made cluster functions such as Distributed Resource Scheduler (DRS) and others independent of the availability of the vCenter Server Appliance (VCSA) for the first time. The latter still represents a single point of failure in the cluster. By outsourcing the DRS function to the redundant vCLS machines, a higher degree of resilience has been achieved.
Retreat Mode
The vSphere administrator has little influence on the provisioning of these VMs. Occasionally, however, it is necessary to remove these VMs from a datastore if it is to be put into maintenance mode, for example. There is a procedure for setting the cluster to retreat mode. This involves setting temporary advanced settings that lead to the deletion of the vCLS VMs by the cluster.
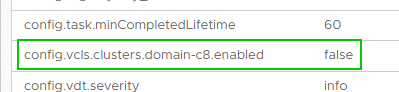
According to the VMware procedure, the Domain ID must be determined to activate Retreat Mode. The domain ID is the numerical value between ‘domain-c’ and the following colon. In the example from my lab, it has the value 8, but the number can also have four digits or more.
The domain ID has to be transferred to the Advanced Settings of the vCenter.
config.vcls.clusters.domain-c8.enabled = false
Correct Retreat Mode settings.
Admin error occured during activation of retreat mode.
After activating retreat mode on a vSAN cluster, administrators had lost all privileges to all objects in the vSphere Client.
A review of the services showed that the vCenter Server Daemon (vpxd) was not running.
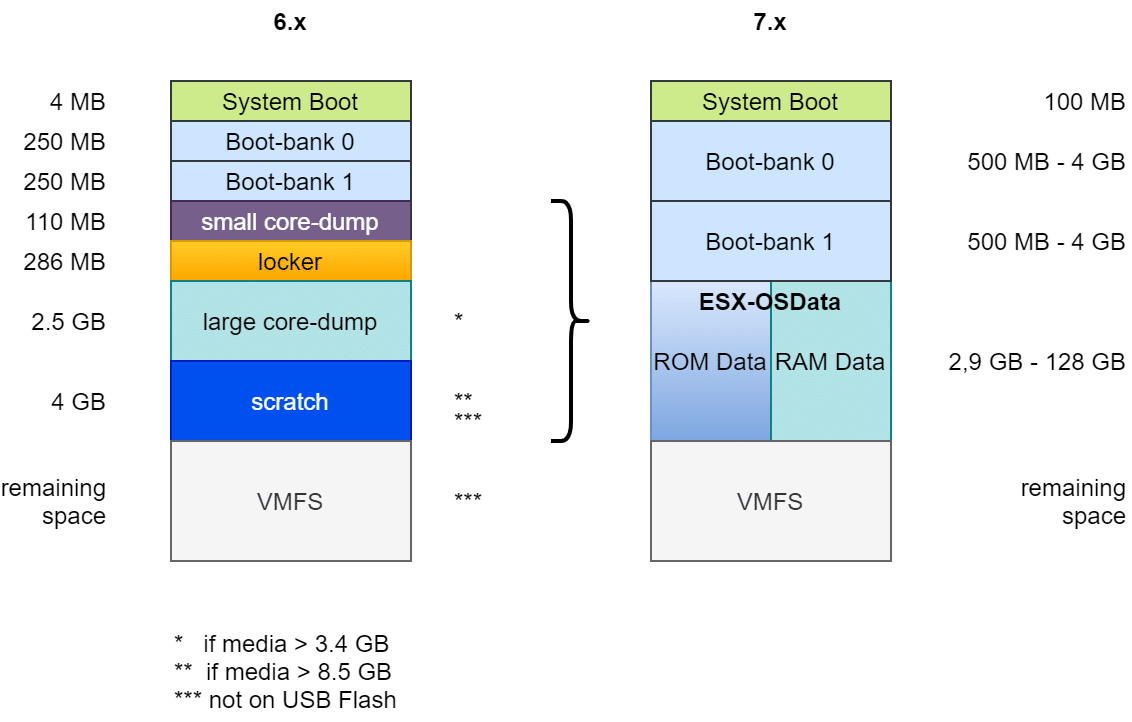
USB boot media did not turn out to be robust enough and were therefore no longer supported from v7U3 onwards. It is still possible to install ESXi on USB media, but the ESX-OSData partition needs to be redirected to permanent storage.
Warning! USB media and SD cards should not be used for production ESXi installations!
Valid setup targets for ESXi deployments
SD cards and USB media are unsuitable as installation targets due to their poor write endurance. Magnetic discs, SSDs and SATA DOMs (disc-on-modules) are still permitted and recommended.
SATA-DOM on a Supermicro E300-9D
New requirements from version ESXi v8 onwards
My Homelab previously used vSAN 7 and thus the classic OSA architecture. To run the cluster under the new vSAN ESA architecture, it was necessary to use vSphere 8 and new storage devices.
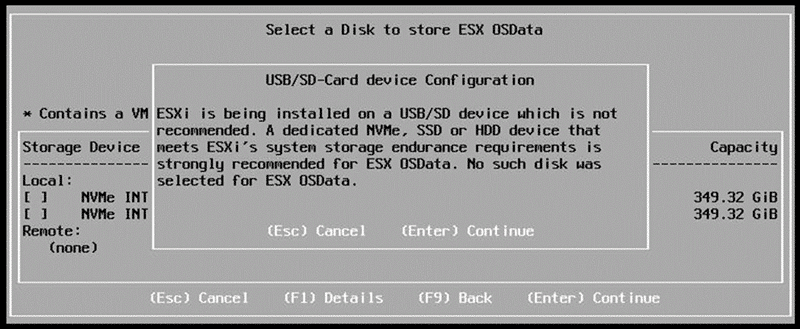
I tested the installation and hardware compatibility on a 64 GB USB medium (not recommended and not supported!). During the installation, there were warnings regarding the USB medium as expected. Nevertheless, I was able to successfully test the detection of the NVMe devices and the vCenter deployment.
Setup warning when trying to use an USB flash medium.
Having successfully completed the test phase, I installed ESXi 8U2 on the SATA DOM of my Supermicro E300 server. To my surprise, the setup failed at a very early stage with the message: “disk device does not support OSDATA“.
RTFM
The explaination is simple: “Read the fine manual!”
My 16 GB SATA DOM from Supermicro was simply too small.
For best performance of an ESXi 8.0 installation, use a persistent storage device that is a minimum of 32 GB for boot devices. Upgrading to ESXi 8.0 requires a boot device that is a minimum of 8 GB. When booting from a local disk, SAN or iSCSI LUN, at least a 32 GB disk is required to allow for the creation of system storage volumes, which include a boot partition, boot banks, and a VMFS-L based ESX-OSData volume. The ESX-OSData volume takes on the role of the legacy /scratch partition, locker partition for VMware Tools, and core dump destination.
VMware vSphere product doumentation
In other words: New installations will require a boot medium of at least 32 GB (128 GB recommended) and upgrading from an ESXi v7 version will require at least 8 GB, but the OSData partition of this installation must already be redirected to an alternate storage device.
Dirty Trick?
Needless to say, I tried a dirty trick. I first successfully installed an ESXi 7U3 on the 16 GB SATA DOM and then performed an upgrade installation to v8U2. This attempt also failed, as the OSData area was not redirected in the fresh v7 installation.
I don’t want to install on USB media as I have seen too many cases where these devices have failed. The only option is to invest in a larger SATA DOM.
I opted for the 64 GB model because it is a good compromise between minimum requirements and cost-effectiveness.