

Admission Control ist Teil der vSphere High Availability (HA) Funktion. Sie stellt sicher, dass im Falle eines Hostfehlers genügend Reserve-Ressourcen für den VM Neustart im Cluster verfügbar sind. Admission Control verhindert den Start von VMs, wenn dadurch diese Reserve überschritten würde.
Seit Version 6.5 gibt es eine dynamische Berechnung der notwendigen Ressourcen, abhängig von der gewünschten Zahl an Hostfehlern, die toleriert werden sollen.
Beginnen wir mit einem Beispiel: Ein Cluster mit zwei gleichen Hosts, der einen Hostausfall tolerieren sollte. Admission Control wird sicherstellen, daß weder CPU, noch RAM zu mehr als 50% belegt werden. Sollte ein Host ausfallen, wird der verbleibende Host genügend Ressourcen haben, um die VMs des ausgefallen Hosts neu zu starten.
Stellen wir uns nun vor, dass wir diesem Cluster zwei weitere Hosts hinzufügen. Die Anzahl der möglichen Host Ausfälle ist weiterhin 1. Jetzt tritt jedoch die dynamische Berechnung in Kraft. Admission Control wird nun eine Ressourcen Auslastung von bis zu 75% erlauben, bevor der Start weiterer VMs unterbunden wird.
Daas ist großartig. Denn nun muss man nur einmalig die Zahl der möglichen Hostfehler definieren und HA Admission Control übernimmt die dynamische Berechnung der nutzbaren Cluster Ressourcen. Das funktioniert sowohl für das Hinzufügen, als auch für das Entfernen von Hosts.
Wartungsmodus
Es gibt hier jedoch ein Problem (oder Feature?), das man im Auge behalten muss. Hosts im Wartungsmodus werden behandelt, als habe man sie aus dem Cluster entfernt. – also nicht wie ein Hostausfall. Daher werden Hosts im Wartungsmodus aus der Berechnung ausgeklammert. Ich habe dies nicht für möglich gehalten, bis ich mich im Buch der Bücher davon überzeugt habe.
[]..if a host is placed into maintenance mode or disconnected, it is taken out of the equation. This also implies that if a host has failed or is not responding but has not been removed from the cluster, it is still included in the equation.
vSphere 6.7 Clustering Deep Dive (Denneman, Epping, Hagoort); P1,Ch7
Klingt zunächst einmal nicht kritisch und ich bin sicher, dies vielfach überlesen zu haben. Erst kürzlich wurde ich jedoch wachgerüttelt, als ich die Konsequenzen in einem Produktivsystem sah.
- Anzahl der Hosts in einem HA Cluster: 4
- Anzahl der zu tolerierenden Hostfehler: 2
- Belegung RAM: 28 %

Das Bild unten zeigt den Speicherverbrauch und die Reservierung für potenzielle zwei Ausfälle durch Admission Control.
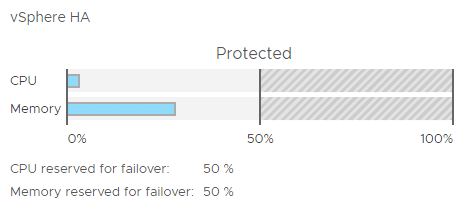
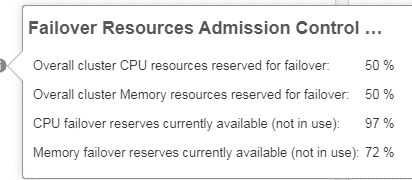
Aktuell sieht alles gut aus. Wir haben 72% freie Arbeitsspeicher Ressourcen im Cluster. Selbst wenn wir die Hälfte aller Hosts verlören, gäbe es noch genügend Ressourcen um alle betroffenen VMs neu zu starten und deren Verfügbarkeit zu garantieren.
Für eine geplante Hardware-Wartung wurde einer der vier Hosts in den Wartungsmodus versetzt. Das sollte im Prinzip kein Problem sein, denn Admission Controll trägt Sorge dafür dass wir zwei Hosts verlieren könnten – richtig? Nein, leider falsch!
Dadurch dass ein Host in den Wartungsmodus wechselte, veränderte sich die gesamte Situation dramatisch. Admission Control verweigerte sofort den Start von VMs (was nebenbei bemerkt, in einer VDI Umgebung recht häufig vorkommt). Die Erklärung des Phänomens ist die, dass Admission Control den Host im Wartungsmodus nicht wie einen ausgefallen, sondern einen entfernten Host betrachtet und diesen daher aus der Berechnung herausnimmt. Das bedeutet, unsere neue Resourcenberechnung basiert nun auf drei Hosts, nicht auf vier. In Ordnung, aber es sollte doch immer noch genügend Spielraum vorhanden sein, um weitere VMs zu starten – oder? Leider nein! Admission Control hält sein Versprechen, den Ausfall zweier Hosts abzufangen. Das ist sehr sportlich in einem 3-Knoten Cluster (zur Erinnerung: einer wurde aus der Berechnung genommen).
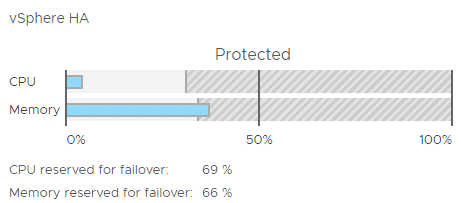
Rechnen wir mal nach…
Um zwei Hostfehler in einem 3-Knoten Cluster zu garantieren, dürfen nur 33% der Gesamtresourcen konsumiert werden. Unser absoluter Speicherbedarf bleibt unverändert, jedoch ändert sich das Verhältnis zu den Gesamtressourcen signifikant. Zuvor hatten wir 28% der Gesamtresourcen beansprucht (berechnet auf 4 Hosts). Mit nun nur noch 3 Hosts müssen wir dieses Verhältnis durch 0,75 teilen und erhalten ein neues Verhältnis von 37%. Das liegt über dem Limit von 33% und Admission Control wird den Start weiterer VMs verweigern.
Gedanken hierzu
Obwohl ich den Gedanken hinter der Berechnung nachvollzehen kann, denke ich dass ein Host im Wartungsmodus wie ein (kontrolliert) abgestürzter Host zu behandeln sei und in der Berechnung berücksichtigt werden solle.
Vielleicht sollte man die Logik von der anderen Seite betrachten. Wenn ein Cluster zwei Hostfehler aushalten sollte und einer der Hosts geht in den Wartungsmodus, dann sollte nur noch ein weiter Ausfall garantiert werden. Oder allgemein ausgedrückt:
%Protected = (1 – [(HFTT – HM) : (Htotal – HM)]) * 100
HFTT : Host Failures to tolerate
Htotal : total number of hosts
HM : hosts in maintenance mode
%Protected : percentage of reserved host resources
Update
Nachdem dieser Post auf Twitter einige Irritationen auslöste, möchte ich nochmals darauf hinweisen, dass es sich hier nicht um einen Fehler handelt, sondern die Berechnungsmethode bewusst gewählt wurde. Ich nannte es ein „Problem“ oder im Englischen „Glitch“, weil die Einstellung irreführend sein kann. Nach meiner Meinung sollte es hier eine Zusatzfunktion geben. Der Anwender sollte im Admission Control Dialog die Wahl zwischen zwei Berechnungsmodellen haben:
- Wenn ein Host in den Wartungsmodus wechselt, soll weiterhin die gewählte Anzahl an potenziellen Hostfehlern garantiert werden. Hosts im Wartungsmodus werden aus der Berechnungsgrundlage entfernt. Reserve Ressourcen für CPU und RAM werden neu berechnet. Aktuelle Ressourcenanforderungen können dabei u.U. die neuen Grenzwerte überschreiten und Admission Control wird das Einschalten weiterer VMs verweigern. Das ist die aktuelle Einstellung.
- Wenn ein Host in den Wartungsmodus wechselt, sollen die Reserven nicht neu berechnet werden. Die Anzahl der zu tolerierenden Hostausfälle wird dabei um eins reduziert. Admission Control wird sich nicht ändern, aber die Verfügbarkeit könnte sich verringern. Der Host im Wartungsmodus wird behandelt wie ein ausgefallener Host. Das ist die gewünschte Erweiterung.
Ich sagte nicht, die Berechnung solle sich ändern. Vielmehr sollte dem Anwender eine Auswahlmöglichkeit gegeben werden, sich für die eine oder andere Variante zu entscheiden. Ein ähnliches Szenario gibt es in vSAN Clustern. Wir hier ein Host in den Wartungsmodus versetzt, erfolgt eine Abfrage, was mit den darauf befindlichen Daten geschehen soll: „Ensure accesibility“ oder „Full data migration„. Geschwindigkeit, oder Sicherheit. Ich denke das wäre der richtige Ansatz.