

Admission control is part of vSphere High Availability (HA). It enforces and ensures availability in case of host failures. It guarantees that there is enough cluster capacity (memory or CPU) left for a HA failover by preventing VM power on actions that would violate that guarantee.
Since vSphere 6.5 there’s a dynamic calculation of minimum required resources, depending on your host number and host failures you want to tolerate.
Let’s start with an example: A cluster got two equal hosts and should tolerate one host failure. Admission control will make sure that neither CPU, nor memory load will exceed 50% of your total resources. If you lose one host there will be enough resources to restart VMs on the remaining host.
Let’s imagine you’re adding another two hosts to the cluster. The number of host failures to tolerate is still 1, but now dynamic resource calculation kicks in. With now four hosts, admission control will allow you to fill up the cluster to 75% before it will prevent VM power on.
That’s great. Because you just have to define your desired number of host failures to tolerate and HA admission control will dynamically calculate the allowed percentage of cluster resources to use. It works for adding and removing hosts likewise.
Maintenance Mode
But there’s a glitch (or feature?) you have to keep in mind. Hosts in mainteinance mode are regarded as host removals – not failures and hence they’re taken out of the equation. I didn’t believe that until I looked it up in the book of books:
[]..if a host is placed into maintenance mode or disconnected, it is taken out of the equation. This also implies that if a host has failed or is not responding but has not been removed from the cluster, it is still included in the equation.
vSphere 6.7 Clustering Deep Dive (Denneman, Epping, Hagoort); P1,Ch7
That doesn’t sound serious and I’m sure I’ve overlooked it while reading the passage in the past. But just recently I got a wakeup call in a real life environment.
- Number of uniform hosts in a HA cluster: 4
- Host failures to tolerate: 2
- Cluster load (memory): 28 %

The picture below shows the cluster’s memory consumption and the reservation by admission control.
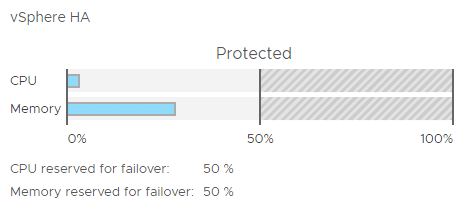
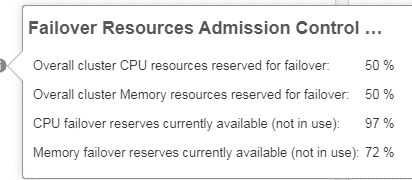
For the moment everything looks fine. We have 72% of unused memory for failover. Even if we’d lose half of our hosts there’d be enough memory resources to restart all VMs and guarantee availability.
For a scheduled hardware maintenance one of our four hosts was set into maintenance mode. Should be no problem, because admission control should make sure we can lose two hosts. Right? No, wrong!
Putting one host into maintenance mode changed the whole situation. Admission control instantly refused to power on VMs (which happens quite often in VDI environments btw.). The explanation of that behavior is that admission control doesn’t treat a host in maintenance mode like a failed host, but took it out of the equation. That means our calculation base is now three hosts – not four. Ok, fair enough. But we still have enough headroom to start more VMs, haven’t we? Sorry, no! Admission control keeps its promise to guarantee two more host failures. That’s very ambitious in a 3-node cluster (remember, one has been taken out of the equation).
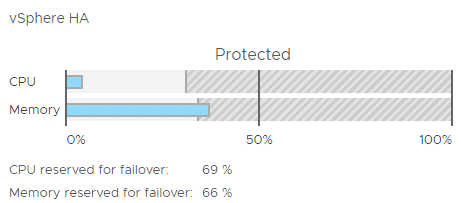
Let’s do the math
In order to guarantee a two host failure in a 3-node cluster you may consume up to 33% of your cluster resources. While our absolute memory consumption remains the same, the ratio will change significantly. Before we had a percentage of consumed memory of 28% (based on four hosts). With 3 hosts we have to divide that ratio by 0.75 and get a new percentage of 37%. That’s more than the limit of 33% and admission control will not allow to power on further VMs.
Thoughts
Although I see the logic behind it (a failure is not a maintenance), I think it would make more sense to treat a maintenance as a (graceful) host failure and keep it in the equation.
Maybe the logic should go the other way round: If a cluster should tolerate two host failures and you put one host in maintenance, admission control should guarantee one more host failure instead of two. Or generally speaking:
%Protected = (1 – [(HFTT – HM) : (Htotal – HM)]) * 100
HFTT : Host Failures to tolerate
Htotal : total number of hosts
HM : hosts in maintenance mode
%Protected : percentage of reserved host resources
Update
After causing some irritation on Twitter, I’d like to point out that the observed behavior is not a malfunction or a glitch. It’s intended by design and there are good reasons to calculate it that way. I called it a ‘glitch’, because the setting might be misleading. IMHO there’s a missing feature. You should have a choice in admission control dialogue:
- When putting a host into maintenance mode ensure number of host failures to tolerate can be fulfilled. Hosts in maintenance are removed from the calculation base and resources are re-calculated and current memory / CPU entitlement may exceed cluster reservations. This is the current setting.
- When putting a host into maintenance mode do not re-calculate cluster resources. Current number of host failures to tolerate will be decreased by 1. Admission control will not change, but availability might be reduced. A host in maintenance mode will be treated like a failed host. This is a feature request.
I’m not saying the calculation should change. I’m saying there needs to be an extra choice. Look at vSAN for example. If you put a host into maintenance mode, vSAN asks you what to do: “ensure accesibility” or “full data migration“. Speed or security. I think that’s the way to go.