
Dies ist ein mehrteiliger Artikel rund um das Produkt VMware Bitfusion. Ich werde eine Einführung in die Technik geben, wie man einen Bitfusion Server einrichtet und wie man dessen Dienste aus Kubernetes Pods nutzen kann.
- Teil 1 : Eine Einführung in Bitfusion
- Teil 2 : Bitfusion Server Setup
- Teil 3 : Bitfusion aus Kubernetes Pods und TKGS ansprechen.
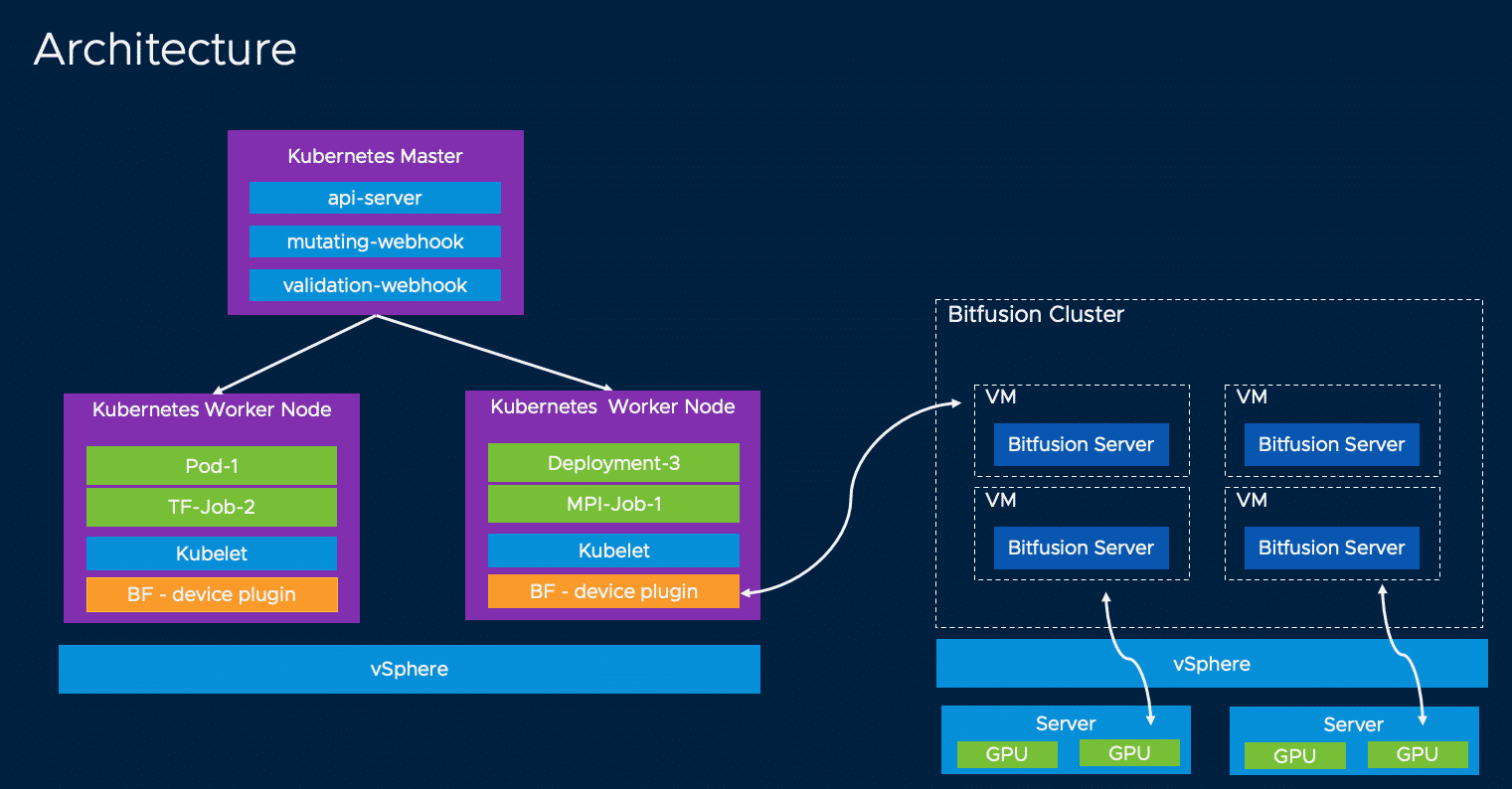
Wir haben in den Teilen 1 und 2 gesehen, was Bitfusion ist und wie man einen Bitfusion Server Cluster aufsetzt. Der herausfordernde Teil ist, diesen Bitfusion Cluster aus Kubernetes Pods nutzbar zu machen.
Damit Container auf Bitfusion GPU-Ressourcen zugreifen können, müssen ein paar Rahmenbedingugen erfüllt sein.
Ich setze in dieser Anleitung voraus, dass wir einen konfigurierten vSphere-Tanzu Cluster zur Verfügung haben, sowie einen Namespace, einen User, eine Storage-Class und die Kubernetes CLI Tools. Das Netzwerk kann entweder mit NSX-T oder mit Distributed-vSwitches und einem Loadbalancer wie zum Beispiel dem AVI-Loadbalancer organisiert sein.
Im beschriebenen PoC wurde aus Gründen der Einfachheit Tanzu on vSphere ohne NSX-T verwendet. Zum Einsatz kam der AVI-Loadbalancer, der jetzt offiziell NSX-Advanced-Loadbalancer genannt wird.
Außerdem benötigen wir ein Linux System mit Zugriff auf Github oder einen Mirror für die Vorbereitung des Clusters.
Der Ablauf ist folgender:
- TKGS Cluster erzeugen
- Bitfusion Baremetal Token laden und K8s Secret erzeugen
- Git Projekt laden und Makefile anpassen
- Device-Plugin auf TKGS-Cluster bereitstellen
- Pod Deployment
TKGS-Cluster erzeugen
Login zu Tanzu Supervisor Control Plane.
kubectl vsphere login --vsphere-username <user> -server=https://<Controlplane> --insecure-skip-tls-verify
In den gewünschten Namespace wechseln
kubectl config use-context <namespace-name>
YAML File für Guest Cluster Deployment erzeugen.
apiVersion: run.tanzu.vmware.com/v1alpha1 kind: TanzuKubernetesCluster metadata: name: <cluster-name> namespace: <namespace-name> spec: topology: controlPlane: count: 1 class: best-effort-large storageClass: <storage-policy> workers: count: 3 class: best-effort-large storageClass: <storage-policy> volumes: - name: containerd mountPath: /var/lib/containerd capacity: storage: 32Gi distribution: version: v1.19
Die Master- und Worker-Node Spezifikationen wurden hier im Beispiel mit Formfaktor „best-effort-large“ erzeugt. Diese sind zweckmäßigerweise den eigenen Bedürfnissen anzupassen. Auch die Anzahl der Master Knoten wurde auf 1 beschränkt, da es sich um eine Testumgebung handelt. In produktiven Umgebungen wäre die zweckmäßige Anzahl 3.
Verfügbare Formfaktoren können abgerufen werden mit:
kubectl get virtualmachineclasses
Vor allem die Kategorie „best-effort“ oder „guaranteed“ sollten Beachtung finden. Bei guaranteed werden Ressourcen exklusiv reserviert. Sind alle Ressourcen gebucht, können keine weiteren Master- oder Workernodes ausgerollt werden. Best-effort versucht die Ressourcen bereitzustellen, kann diese aber nicht garantieren. Werden weitere Worker und Master ausgerollt, müssen diese sich die vorhandenen Ressourcen teilen und es kann zu Leistungseinbußen kommen.
Weitere Info in der VMware Dokumentation: Virtual Machine Classes for Tanzu Kubernetes Clusters
Deployment anwenden
kubectl apply -f cluster-deployment.yaml
Nach Absetzen des Befehls muss gewartet werden, bis der neue Cluster komplett erzeugt wurde. Der Status kann mit describe kontrolliert werdem.
kubectl describe tkc <clustername>
Der Cluster muss vollständig im Status „Ready“ sein.
Anmelden am neuen TKGS-Cluster
kubectl-vsphere login --vsphere-username <username> --server=https://<Supervisor-Control-Plane> --insecure-skip-tls-verify --tanzu-kubernetes-cluster-namespace=<namespace-name> --tanzu-kubernetes-cluster-name=<cluster-name>
Erweiterte Rechte setzen, damit der Benutzer Pods erzeugen darf:
kubectl create clusterrolebinding default-tkg-admin-priviledged-binding --clusterrole=psp:vmware-system-privileged --group=system:authenticated
Token erzeugen
Damit ein Client (Pod, VM, etc.) auf eine Bitfusion GPU Ressource zugreifen kann, muss zunächst ein Secret (Token) im Tanzu Namespace erzeugt werden. Dieses Token muss im Containerimage bereitgestellt werden, was die Verwendung allgemein verfügbarer Images erschwert.
Alternativ kann auch das Bitfusion Device-Plugin verwendet werden. Letzteres ist die empfohlene Methode.
Das Token wird in der Bitfusion GUI des vCenters erzeugt. Menu > Bitfusion > Tokens > New Token. Über Download kann das Token als TAR-Archiv heruntergeladen und mit SCP auf die Linux Helper-VM übertragen werden.
Wir erzeugen ein Verzeichnis ‚tokens‘, in das das Tarfile entpackt wird.
mkdir tokens tar -xvf <tarfile> -C tokens
Im Verzeichnis ‚tokens‘ werden drei Dateien ca.crt, client.yaml und servers.conf entpackt.
kubectl create secret generic bitfusion-secret --from-file=tokens -n kube-system
Device Plugin
Das Device Plugin vereinfacht die Konsumierung und Buchung von GPU-Ressourcen während der Laufzeit eines Pods. Der Bitfusion-Client wird damit automatisch bereitgestellt. Die Verwendung des Device-Plugins ist nicht zwingend erforderlich, erleichtert jedoch den Anwendern die Arbeit mit Bitfusion erheblich. Diese können aud Container Workloads GPU Ressourcen buchen, ohne sich um den Bitfusion Client kümmern zu müssen.
Dokumentation der bitfusion-with-kubernetes-integration (bwki) auf GitHub.
Wird das Device-Plugin nicht verwendet, so muss die GPU im Pod manuell zugeteilt werden. Beispielsweise mit entsprechenden Python Befehlen.
bitfusion run –n 1 python3
Device-Plugin bereitstellen
git clone https://github.com/vmware/bitfusion-with-kubernetes-integration.git
cd bitfusion-with-kubernetes-integration-main/bitfusion_device_plugin
Makefile anpassen.
IMAGE_REPO ?= docker.io/bitfusiondeviceplugin DEVICE_IMAGE_NAME ?= bitfusion-device-plugin WEBHOOK_IMAGE_NAME ?= bitfusion-webhook PKG_IMAGE_NAME ?= bitfusion-client IMAGE_TAG ?= 0.2 K8S_PLATFORM ?= community
In der Regel muss hier nur die URL zum Repository angepasst werden. Mit make deploy werden die notwendigen Komponenten bereitgestellt.
make deploy
Anpassung des Deployment YAML zur Buchung von GPU
Bei Verwendung des Device-Plugins können die Ressourcen im Deployment gebucht werden. Die Anwender müssen keine Bitfusion Kenntnisse haben, um diese Ressource nutzen zu können.
spec:
containers:
resources:
limits:
bitfusion.io/gpu-num: 1
bitfusion.io/gpu-percent: 25
Im Beispiel oben wurde eine physische GPU zu 25% gebucht. Die prozentuale Angabe bezieht sich auf das GPU RAM und nicht auf Cores oder Rechenzeit.
Damit das Bitfusion Device-Plugin verwendet werden kann, muss es im TKGS-Cluster installiert werden. Zur Bereitstellung ist ein Linux Hilfssystem für die Compilierug notwendig.
Danksagung
Dieser Blogartikel wurde möglich durch die sehr gute Zusammenarbeit zwischen VMware, Kunde und Dienstleister. Mein besonderer Dank gilt an dieser Stelle Sabine, Christian und Torsten, die maßgeblich zum Erfolg des Projekts beigetragen haben. Danke auch an das VMware Team Jim Brogan, Kevin Hu und Christopher Banck, für die Unterstützung jenseits der Dokumentation.