
This will be a multi-part post focused on the VMware Bitfusion product. I will give an introduction to the technology, how to set up a Bitfusion server and how to use its services from Kubernetes pods.
- Part 1 : A primer to Bitfusion
- Part 2 : Bitfusion server setup
- Part 3 : Using Bitfusion from Kubernetes pods and TKGS. (this article)
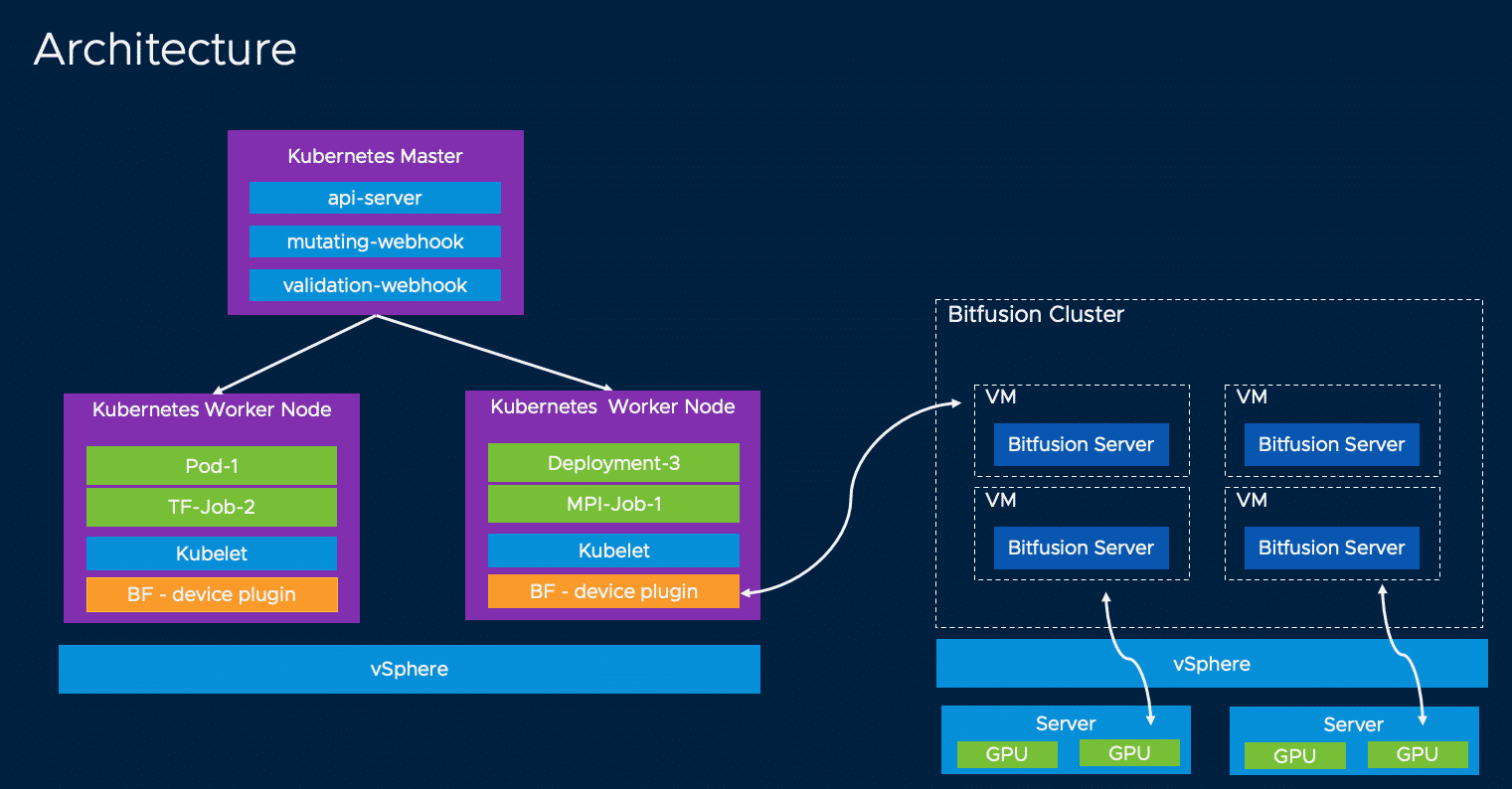
We saw in parts 1 and 2 what Bitfusion is and how to set up a Bitfusion Server cluster. The challenging part is to make this Bitfusion cluster usable from Kubernetes pods.
In order for containers to access Bitfusion GPU resources, a few general conditions must be met.
I assume in this tutorial that we have a configured vSphere-Tanzu cluster available, as well as a namespace, a user, a storage class and the Kubernetes CLI tools. The network can be organized with either NSX-T or distributed vSwitches and a load balancer such as the AVI load balancer.
In the PoC described, Tanzu on vSphere was used without NSX-T for simplicity. The AVI load balancer, now officially called NSX-Advanced load balancer, was used.
We also need a Linux system with access to Github or a mirror to prepare the cluster.
The procedure in a nutshell:
- Create TKGS cluster
- Get Bitfusion baremetal token laden and create K8s secret
- Load Git project and modify makefile
- Deploy device-plugin to TKGS-cluster
- Pod deployment
Create TKGS-cluster
Login into Tanzu Supervisor Control Plane.
kubectl vsphere login --vsphere-username <user> -server=https://<Controlplane> --insecure-skip-tls-verify
Change namespace
kubectl config use-context <namespace-name>
Create YAML file for guest cluster deployment.
apiVersion: run.tanzu.vmware.com/v1alpha1 kind: TanzuKubernetesCluster metadata: name: <cluster-name> namespace: <namespace-name> spec: topology: controlPlane: count: 1 class: best-effort-large storageClass: <storage-policy> workers: count: 3 class: best-effort-large storageClass: <storage-policy> volumes: - name: containerd mountPath: /var/lib/containerd capacity: storage: 32Gi distribution: version: v1.19
The master and worker node specifications were created here in the example with the “best-effort-large” form factor. It is recommended that these are adapted to the user’s own requirements. The number of master nodes was also limited to 1, as this is a test environment. In productive environments, the recommended number would be 3.
You can list available form factors with the command:
kubectl get virtualmachineclasses
Especially the category “best-effort” or “guaranteed” should be considered. With guaranteed, resources are reserved exclusively. If all resources are booked, no further master or worker nodes can be rolled out. Best-effort tries to provide the resources, but cannot guarantee them. If additional workers and masters are rolled out, they have to share the available resources and this can lead to performance issues.
There’s further information in the VMware documentation: Virtual Machine Classes for Tanzu Kubernetes Clusters
Apply cluster deployment
kubectl apply -f cluster-deployment.yaml
After issuing the command, you must wait until the new cluster has been completely created. The status can be checked with the command describe.
kubectl describe tkc <clustername>
The new cluster has to be fully in condition ‘ready’.
Login to newTKGS-cluster
kubectl-vsphere login --vsphere-username <username> --server=https://<Supervisor-Control-Plane> --insecure-skip-tls-verify --tanzu-kubernetes-cluster-namespace=<namespace-name> --tanzu-kubernetes-cluster-name=<cluster-name>
Set extended permissions to allow the user to create pods:
kubectl create clusterrolebinding default-tkg-admin-priviledged-binding --clusterrole=psp:vmware-system-privileged --group=system:authenticated
Create token
In order for a client (pod, VM, etc.) to access a Bitfusion GPU resource, a secret (token) must first be created in the Tanzu namespace. This token must be provisioned in the container image, which makes it difficult to use commonly available images.
Alternatively, the Bitfusion Device plugin can be used. That’s the recommended method.
The token is created in the Bitfusion GUI of the vCenter. Menu > Bitfusion > Tokens > New Token. The token can be downloaded as a TAR archive and transferred to the Linux helper VM using SCP.
We’ll create a directory ‘tokens’ into which the tarfile is unpacked.
mkdir tokens tar -xvf <tarfile> -C tokens
In the directory ‘tokens’ three files ca.crt, client.yaml and servers.conf are untarred.
kubectl create secret generic bitfusion-secret --from-file=tokens -n kube-system
Device Plugin
The Device Plugin simplifies the consumption and booking of GPU resources during the pod runtime. It automatically provisions the Bitfusion client. Using the device-plugin is not mandatory, but it makes it much easier for users to work with Bitfusion. They can book GPU resources for container workloads without having to worry about the Bitfusion client.
Documentation for bitfusion-with-kubernetes-integration (bwki) on GitHub.
If the device plugin is not used, the GPU in the pod must be allocated manually. For example, with the corresponding Python commands.
bitfusion run –n 1 python3
Deploy the device-plugin
git clone https://github.com/vmware/bitfusion-with-kubernetes-integration.git
cd bitfusion-with-kubernetes-integration-main/bitfusion_device_plugin
Adjust makefile
IMAGE_REPO ?= docker.io/bitfusiondeviceplugin DEVICE_IMAGE_NAME ?= bitfusion-device-plugin WEBHOOK_IMAGE_NAME ?= bitfusion-webhook PKG_IMAGE_NAME ?= bitfusion-client IMAGE_TAG ?= 0.2 K8S_PLATFORM ?= community
Typically, only the URL to the repository needs to be modified here. The required components are deployed with make deploy.
make deploy
Customization of the deployment YAML for the booking of GPU
When using the Device plugin, the resources can be booked in the deployment. Users do not need to have Bitfusion skills to use this resource.
spec:
containers:
resources:
limits:
bitfusion.io/gpu-num: 1
bitfusion.io/gpu-percent: 25
In the example above, one physical GPU was booked by 25%. The percentage refers to the GPU RAM and not to cores or computing time.
In order to use the Bitfusion Device Plugin, it must be installed in the TKGS cluster. A Linux helper system for compilation is required for deployment.
Acknowledgements
This blog article was made possible by the very good cooperation between VMware, the customer and the consultant. My special thanks go to Sabine, Christian and Torsten, who contributed significantly to the success of the project. Thanks also to the VMware team Jim Brogan, Kevin Hu and Christopher Banck, for their support beyond the technical documentation.