You don’t need an enterprise cluster in order to get an impression of VMware Tanzu and Kubernetes. Thanks to the Tanzu Community Edition (TCE), now anyone can try it out for themselves – for free. The functionality offered is not limited in comparison to commercial Tanzu versions. The only thing you don’t get with TCE is professional support from VMware. Support is provided by the community via forums, Slack groups or Github. This is perfectly sufficient for a PoC cluster or the CKA exam training.
Deployment is pretty fast and after a couple of minutes you will have a functional Tanzu cluster.

TCE Architecture
The TCE can be deployed in two variants either as a standalone cluster or as a managed cluster.
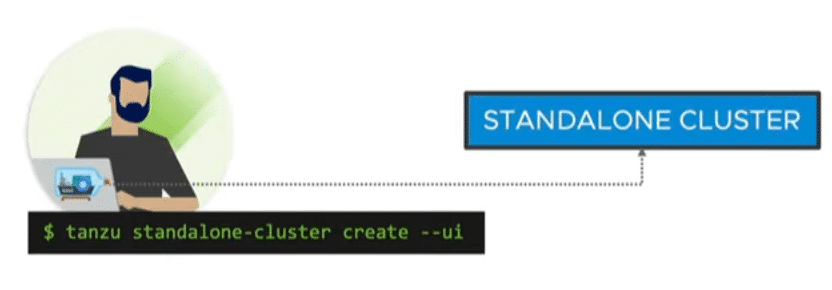
Standalone Cluster
A fast and resource-efficient way of deployment without a management cluster. Ideal for small tests and demos. The standalone cluster offers no lifecycle management. Instead, it has a small footprint and can also be used on small environments.
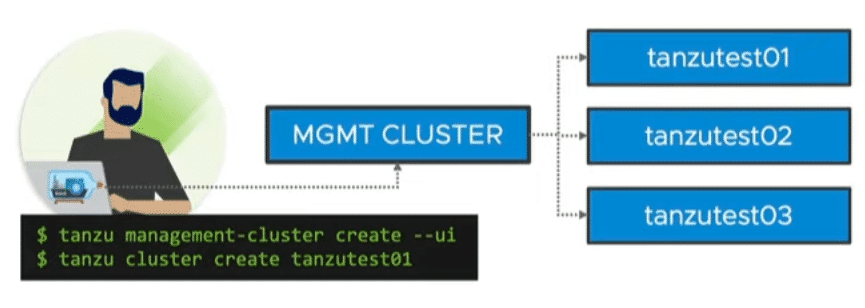
Managed Cluster
Like commercial Tanzu versions, there is a management cluster and 1 to n workload clusters. It comes with lifecycle management and cluster API. Thus, declarative configuration files can be used to define your Kubernetes cluster. For example, the number of nodes in the management cluster, the number of worker nodes, the version of the Ubuntu image or the Kubernetes version. Cluster API ensures compliance with the declaration. For example, if a worker node fails, it will be replaced automatically.
By using multiple nodes, the managed cluster of course also requires considerably more resources.
Deployment options
TCE can be deployed either locally on a workstation by using Docker, in your own lab/datacenter on vSphere, or in the cloud on Azure or aws.
I have a licensed Tanzu with vSAN and NSX-T integration up and running in my lab. So TCE on vSphere would not really make sense here. Cloud resources on aws or Azure are expensive. Therefore, I would like to describe the smallest possible and most economical deployment of a standalone cluster using Docker. To do so, I will use a VM on VMware workstation. Alternatively, a VMware player or any other kind of hypervisor can be used.
Continue reading “Running Tanzu Community Edition on a Linux VM – Simple Walkthrough for Beginners”