This is a brief guide on how to upgrade Tanzu Workload Management within the vSphere cluster.
Kubernetes Release and Patch Cycles
Kubernetes versions are specified as x.y.z following Semantic Versioning terminology, where x is the major version, y is the minor version, and z is the patch version. For example, v1.22.6 denotes a minor version 22 with patch level 6. Minor versions are released approximately every 3-4 months. In the meantime, there are several patches within the minor version.
The Kubernetes project maintains release branches for the last three minor versions (1.24, 1.23, 1.22). Since Kubernetes 1.19, newer versions receive patch support for about a year. So keeping the Kubernetes versions in Tanzu up to date is highly recommended.
Step 1 – Update vCenter
This step is not mandatory, but recommended. Updates on vCenter are often accompanied by a new Kubernetes versions. You can see notifications about updates in the vSphere Client.
In the last few years we’ve seen a clear trend to adopt cloud strategies on customer side. Some already pusue a multi cloud strategy to get the most benefit from different offerings. But we may not forget, that infrastructure on-premises – the so called private cloud – is still the most common kind of virtual infrastructure. This is no surprise because on-premises infrastructure has without doubt some advantages. It’s not alone aspects of data privacy, data security and data sovereignty. There are also performance aspects such as low latency that keep customers from migration special workloads to the (public) cloud.
On the other hand there are some advantages of cloud offerings too. Such as flexible consumption, minimal maintenance, built in resilience, developer agility and the possibility to manage from anywhere.
To bridge the gap between on-premises needs and cloud based offerings, VMware has announced Project Arctic during VMworld 2021. Delivering benefits of the cloud to on-premises workloads.
Added Network Security Policy support for VMs deployed via VM operator service – Security Policies on NSX-T can be created via Security Groups based on Tags. It is now possible to create NSX-T based security policy and apply it to VMs deployed through VM operator based on NSX-T tags.
Supervisor Clusters Support Kubernetes 1.22 – This release adds the support of Kubernetes 1.22 and drops the support for Kubernetes 1.19. The supported versions of Kubernetes in this release are 1.22, 1.21, and 1.20. Supervisor Clusters running on Kubernetes version 1.19 will be auto-upgraded to version 1.20 to ensure that all your Supervisor Clusters are running on the supported versions of Kubernetes.
Check before update
If you upgraded vCenter Server from a version prior to 7.0 Update 3c and your Supervisor Cluster is on Kubernetes 1.9.x, the tkg-controller-manager pods go into a CrashLoopBackOff state, rendering the guest clusters unmanageable
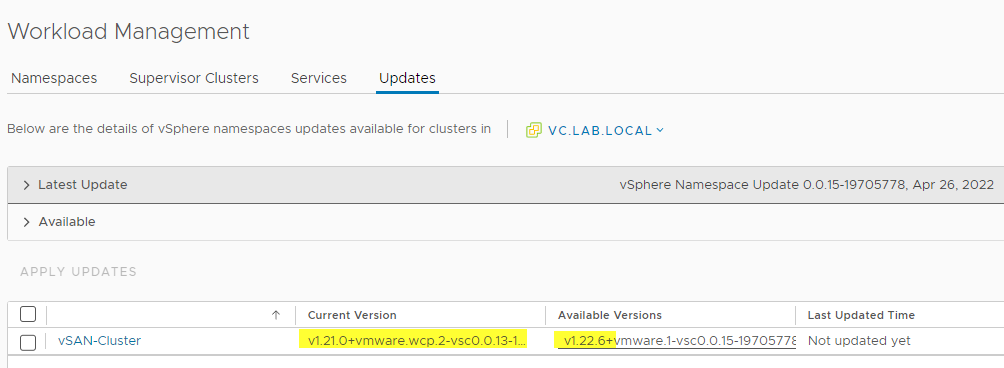
The image above indicates we’re already on version 1.21, which is good for an update.
Update
Before updating your VCSA make sure you have a configuration backup! An optional VM snapshot is a good idea too. It might help to revert settings fast in case something goes wrong.
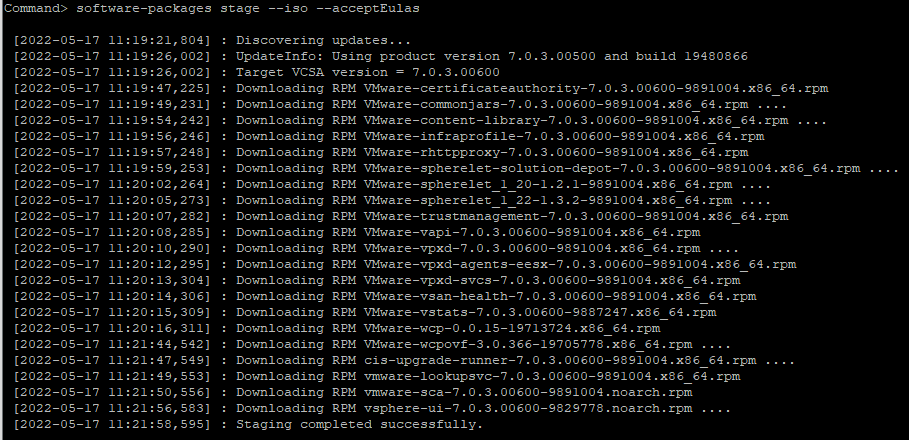
You can either apply the update from VAMI or from the shell. The image below shows an overview of the new packages with this update.
After the update is installed you will have an option to deploy a new Kubernetes version in your Supervisor Control Plane.
You don’t need an enterprise cluster in order to get an impression of VMware Tanzu and Kubernetes. Thanks to the Tanzu Community Edition (TCE), now anyone can try it out for themselves – for free. The functionality offered is not limited in comparison to commercial Tanzu versions. The only thing you don’t get with TCE is professional support from VMware. Support is provided by the community via forums, Slack groups or Github. This is perfectly sufficient for a PoC cluster or the CKA exam training.
Deployment is pretty fast and after a couple of minutes you will have a functional Tanzu cluster.
TCE Architecture
The TCE can be deployed in two variants either as a standalone cluster or as a managed cluster.
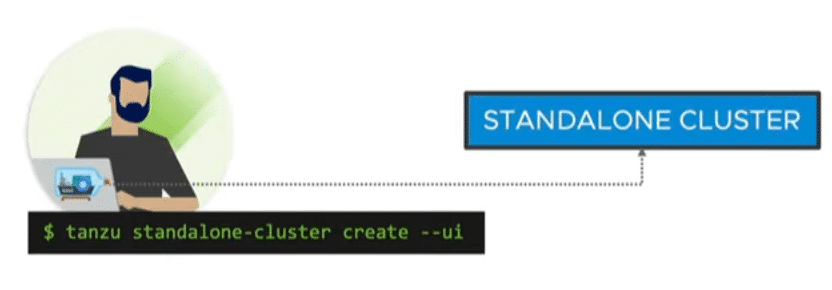
Standalone Cluster
A fast and resource-efficient way of deployment without a management cluster. Ideal for small tests and demos. The standalone cluster offers no lifecycle management. Instead, it has a small footprint and can also be used on small environments.
Source: VMware
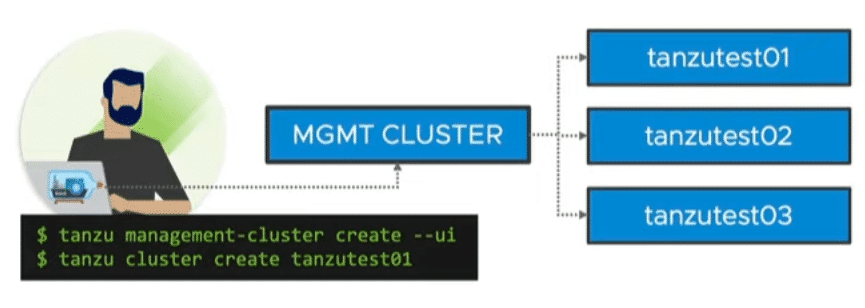
Managed Cluster
Like commercial Tanzu versions, there is a management cluster and 1 to n workload clusters. It comes with lifecycle management and cluster API. Thus, declarative configuration files can be used to define your Kubernetes cluster. For example, the number of nodes in the management cluster, the number of worker nodes, the version of the Ubuntu image or the Kubernetes version. Cluster API ensures compliance with the declaration. For example, if a worker node fails, it will be replaced automatically.
By using multiple nodes, the managed cluster of course also requires considerably more resources.
Source: VMware
Deployment options
TCE can be deployed either locally on a workstation by using Docker, in your own lab/datacenter on vSphere, or in the cloud on Azure or aws.
I have a licensed Tanzu with vSAN and NSX-T integration up and running in my lab. So TCE on vSphere would not really make sense here. Cloud resources on aws or Azure are expensive. Therefore, I would like to describe the smallest possible and most economical deployment of a standalone cluster using Docker. To do so, I will use a VM on VMware workstation. Alternatively, a VMware player or any other kind of hypervisor can be used.