
Microsoft’s file system ReFS is around for some time now. Windows 2012 already brought us the initial version almost six years ago. Still we had to wait till Windows Server 2016 appeared to get the real killer feature – at least as far as its usage for Veeam backups is concerned.
Why ReFS for Veeam?
ReFS version 3 brings two great things: support for fast-cloning and for spaceless full backups.
Fast-cloning means all merges following forever-forward and certain synthetic processes (e.g. reverse-incremental) run much faster.
But my hidden champion is the spaceless full backup feature. With it GFS restore points in your backup-copy chains consume much less space on your storage than before.
Get a brief overview in Rick Vanovers blog on this topic: https://www.veeam.com/blog/advanced-refs-integration-coming-veeam-availability-suite.html
Issues? – fixed!
There seemed to be issues on ReFS with very large files with Veeam in the beginning, but since a few weeks Microsoft has fixed that finally. So make sure to install this patch if you don’t want to run into performance or stability issues: https://support.microsoft.com/en-us/help/4077525/windows-10-update-kb4077525
Currently this update is only available through the catalog and not via Windows Updates: http://www.catalog.update.microsoft.com/Search.aspx?q=KB4077525
This is because of issues with another patch in the rollup and it will be available again later. You can get the latest on it in the Veeam forum thread on this: https://forums.veeam.com/veeam-backup-replication-f2/refs-4k-horror-story-t40629-915.html
As you can tell from the URL: don’t use 4k block-sizes with your ReFS repos. Go for 64k instead. And if you want to shiver – read the full forum thread on the problems with ReFS repositories some people had to face in the beginning. But relax – in the many installations I take care of and in our own Veeam cloud provider repository ReFS runs as expected and without issues.
Measure your space savings
Just to recap: spaceless full backups means that the full backups automatically generated in your backup-copy chain because of switching on GFS for the job do not take the full space on the disk needed for the VBK file. Only the blocks differing from the other full backups already in the chain are stored. The rest is done by relinking the same blocks on disk to another file.
This is even better than a dedup storage – this is a storage preventing the “dup” in the first place. So no dedup needed later on.
Unfortunately there is no easy way to determine the amount of savings you get from this feature in the long run. Neither Veeam nor the Windows tools show any hint on the real usage on disk. The VBK files in your dir still look full blown as before:
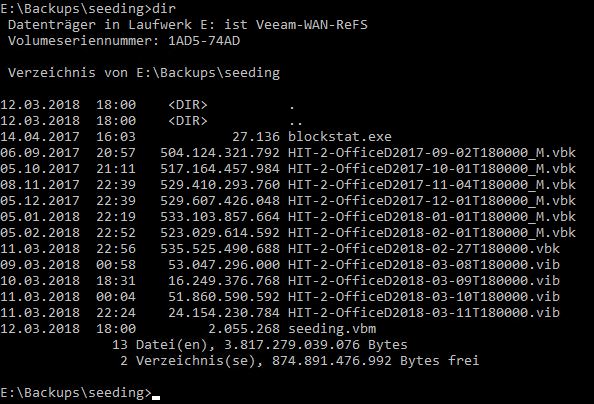
Here we have half a year of auto generated GFS monthlies plus the most recent VBK sitting in a ReFS repository. It looks as if they consume more than 3.5TB (7*500GB).
Fortunately there is a free tool available, that is able to determine the real storage space consumed on disk. Timothy Dewin – the man behind the restore point simulator – created it and even shared its sources: http://dewin.me/refs/
Used on the example above I first generated a text file with a list of the VBK file names:
dir /b *.vbk > vbk.txt
Then I provided blockstat with the file and gave it some time to iterate through all the linked blocks.
blockstat.exe -i "vbk.txt"
This might easily take some minutes. In my case it was half an hour. This obviously depends on the speed of your repositories storage.
But the output shows the features coolness in all its beauty – if you know how to interpret it of course…
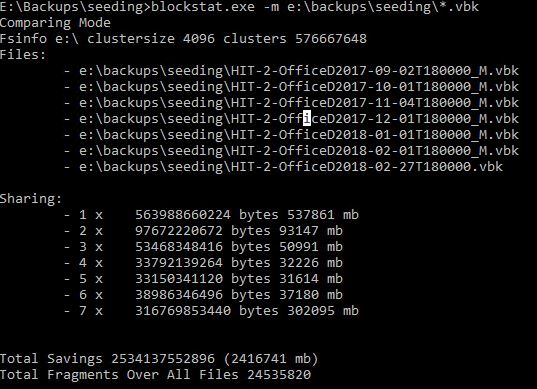
The first line reminds me that my test repository uses 4k block size – which is not recommended as it might lead to performance issues. At least before the fix from Microsoft was released (see above). I would still recommend to always use 64k for productive repositories.
The next part lists all the files taken into account. This should correlate with your input file.
The following block is the interesting part and has to be interpreted correctly. This is basically a histogram of the blocks on disk. It shows us how often the blocks are reference from the seven files. So the maximum can only be seven. 300MB of my data is referenced from all seven files meaning they are stored only once on the drive. 37MB are referenced 6 times. 31MB still 5 times. And so on.
Do your maths – or let Excel do it
To calculate the savings you now have to sum the net blocks by just adding them and compare that to the gross size which is the net-size multiplied by the number of instances these blocks have in each row. The difference of the two sums shows us the savings we have.
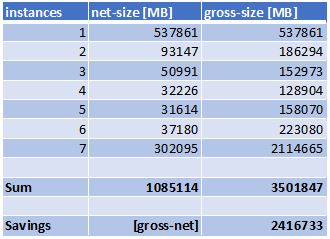
In my case the seven files would regularly have a footprint of 3.5TB. This is also what the directory in Windows shows us. Using spaceless full backups the files in reality only saturate little more than 1TB on the disk. You get seven full backups for the price of two.
Obviously this process must lead to a lot more fragmentation on your disk as your blocks are no longer lined up nicely on your disk. Sometimes a single block might belong to dozens of files. So a fast storage is recommended.
Also if you manually copy the files to another disk or repository the magic fades like a fata morgana in the desert. The files would be sitting there fully hydrated and therefore would for instance not fit back on the disk they originally were copied from. This has to be taken into account when planning maintenance tasks for your repositories. ReFS has still some room to elaborate in its features – but it certainly will.
Who benefits?
We automated the process to read the savings on a regular basis for our cloud provider repositories. Of course we only charge our cloud customers the net size on disk once they leverage GFS in their cloud backups with us. So the benefit is theirs… 🙂
Hi,
Are you willing to share your automation part? We als have different repositories where we want to view the actual use.
Thanks!
blockstat fails with error need at least 2 files to compare and 1 to dump