

Using Exagrid Deduplication Appliances as Veeam Repository
The importance of backup and recovery solutions today is beyond any discussion. Going back 10 years this was a rather neglected topic. But today no-one can afford data loss or services being unavailable. So the importance of backup solutions leveled up with that of production systems. Time windows for RPO and RTO have become smaller and smaller and the effort and cost to achieve that have become higher. If you’re planning a backup strategy, you need to find a good balance between speed, reliability and cost. Low cost NAS boxes are slow and not very reliable. Running an instant recovery from them can turn into a pain. Premium storages are fast and reliable, but also quite expensive. Backup data is in most cases very redundant, which means there’s a high capacity and cost saving potential in deduplication and compression.
Deduplication
There are two ways to apply deduplication: hardware and software.
Backup solutions like Veeam Backup & Recovery offer software deduplication. Here deduplication is applied to the data stream even before data reaches its backup repository.
An alternate approach are deduplication appliances. Usually they receive a raw or dedupe friendly data stream which is then processed in a secondary step. Usually these appliances achieve higher deduplication and compression ratios compared to inline deduplication, because the algorithms have access to the whole dataset and not just a point in time of the stream.
Exagrid
I’d like to present here a deduplication appliance from Exagrid. Their boxes have some additional features compared to those of other vendors – especially when they work in combination with Veeam Backup & Replication.
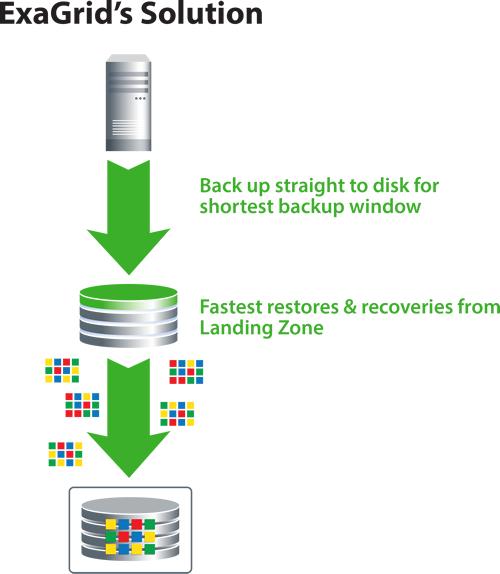
Landing Zone
When backing up to an Exagrid appliance, all data will be placed first in a storage region which is called the landing zone. It will come in almost raw (dedupe friendly). Then deduplication and compression will be applied and the data sent to the archive region. Exagrid appliances keep the latest backup data uncompressed within the landing zone. That keeps the data highly available. More than 90% of all restore operations are made from the latest dataset, so it’s a good idea to keep that set hydrated. Other Deduplication appliances need to recall data from their archives and re-hydrate (de-compress) it before sending it back to the Veeam server, i.e. collecting deduplicated data and undo compression. That process costs a lot of compute power and time and therefore will slow down your recovery.
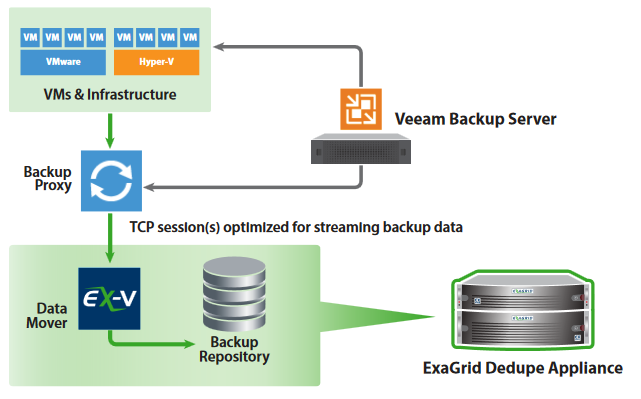
Veeam Datamover
Exagrid appliances do have a deep Veeam integration. Veeam backup service communicates directly with a Veeam datamover built into the appliance. Therefore we have a Veeam-to-Veeam communication which means we can transfer data at high rate to and from the appliance. The integrated Veeam datamover enables the appliance to create synthetic full backups at high speed without leaving the appliance. Other appliances without integrated datamover need to read the latest full backup and increments over CIFS to the Veeam Server (or proxy) and then write the synthetic full back to the appliance over CIFS (again). By leveraging an integrated datamover, there’s no need for this time consuming procedure and synthetic full backups can be up to 6x faster.
Security Aspects
Having a Veeam datamover within the appliance offers a big advantage in the defense against ransomware and cryptolockers. The repository does not expose any CIFS/NFS share to the network. The only way to access the repo is via Veeam (Veeam-to-Veeam). And only Veeam knows the login credentials to get access. So even if some malware compromises ADS and gets hold of an administrative account, it won’t be able to access the backup appliance. This works just like an airgap. For comparison, if you’re using a server with local disks, you’ll need to present a volume to your Veeam server over CIFS, or as an iSCSI target. Either way, if something compromises your admin credentials it will have access to the repository and might be able to encrypt your backup data.
Scale-out grid
Over time backup data might increase and there’ll be need for more storage capacity. Exagrid uses a scale-out grid model to increase backup storage by adding more appliances to existing ones. They then form a grid in which not only capacity is increased, but also compute power, memory and bandwidth. As a result your backup windows will stay more or less constant, even though backup size has increased.
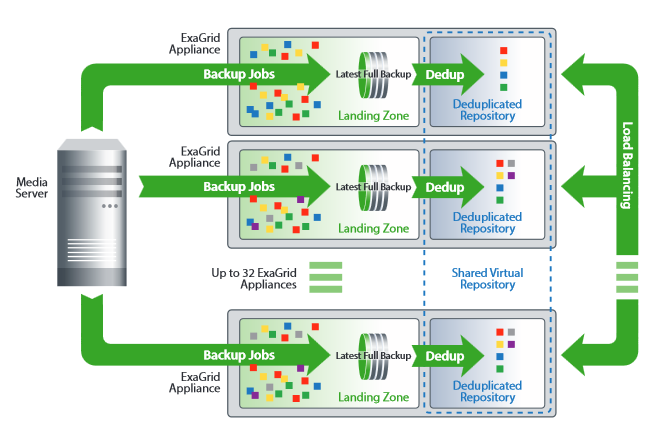
It is possible to add different model series to the grid. Any size or age of appliance can co-exist. There’s no need for expensive forklift upgrades, i.e. replacing existing models with bigger/newer ones. Exagrid calls this approach “pay as you grow”. Start small and scale out.
Performance
Our POC model was an EX21000E-SEC. The Number indicates the amount of raw storage capacity (21 TB) for a full backup in the landing zone. It has another 21 TB capacity in the archive zone. SEC stands for security. This unit has FIPS 140-2 compliant self-encrypting SAS drives.
We’ve tried our best to stress the Exagrid appliance (but we failed). We’ve used it as primary backup repository for 29 production VMs with a total capacity of 4.1 TB. These are real life VMs with true workloads (mail, fileserver, sharepoint, terminalserver, owncloud, developpment, domain controller)
Our POC model was connected via 10 Gbit LAN. The table below also shows another repositry with local NLSAS disks (RAID5) and a ReFS filesystem for comparison. Values are averages over >100 backups.
| Job | Target | Schedule | MB/s | Time [min] |
|---|---|---|---|---|
| Incremental | Exagrid | hourly | 200-300 | 10 |
| Synthetic Full | Exagrid | daily | 200 | 90-120 |
| Incremental | ReFS | daily | 50-90 | 120-160 |
An initial active full to Exagrid (4.1 TB) had a throughput of 460 MB/s on average. Every increment showed a throughput of 200-300 MB/s. Bottleneck was always source.
Deduplication Ratio
With 120 restore points we’ve achieved a deduplication ratio from 8:1 to 10:1 which became better with an increasing number of backups.
![]()