

I usually get a lot of questions during trainings or in the process of vSAN designs. People ask me why there is a requirement for 30% of slack space in a vSAN cluster. If you look at it without going deeper, it looks like a waste of (expensive) resources. Especially with all-flash clusters it’s a strong cost factor. Often this slack space is mistaken as growth reserve. But that’s wrong. By no means it’s a reserve for future growth. On the contrary – it is a short term allocation space, needed by the vSAN cluster for rearrangements during storage policy changes.
Storage Policies
One big advantage of vSAN compared to classic LUN based storage is its flexible object availability. While with classic storage the LUN defines availability and performance, vSAN can define these parameters on VM or vDisk level. You no longer have to migrate a vDisk from a RAID5 to RAID10 LUN. With vSAN it’s just a click with your mouse in vCenter and the VM or the vDisk will get a new policy and vSAN will take care of the required availability.
Temporary storage
To make policy changes possible on the fly, vSAN has to create new objects alongside with the old ones until the policy change is accomplished. Then objects of the old policy can be deleted but during the transition phase there’s an increased requirement for storage space.
Take a look at the example below. There is a vDisk of 120 GB with a mirroring (RAID1) policy and one failure to tolerate (FTT=1). The policy will be changed to erasure coding (EC). Erasure coding is often referred to as RAID5, but it is not RAID5 because the algorithm for parity calculation is totally different.
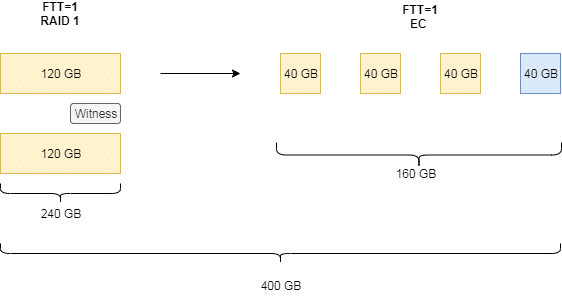
In the example shown above we have the original policy of mirroring (FTT=1). To achieve a failure tolerance of one, vSAN has to place two copies on two different hosts. 120 GB of raw data will result in 240 GB usage on the datastore. As quorum in case of a host isolation there has to be a third component called witness, but its disk usage on the datastore can be neglected.
In order to switch policy to erasure coding, the datadisk will be split into 3 parts and a forth parity component will be calculated. Erasure coding requires 2n+2 hosts, where n equals the amount of failures to tolerate. In our example above n=FTT=1 which requires four components on four different hosts.
Until policy transition is completed there will be objects of the old and new policy side by side. An original requirement of 240 GB (120 GB mirrored) will grow temporarily to 400 GB.
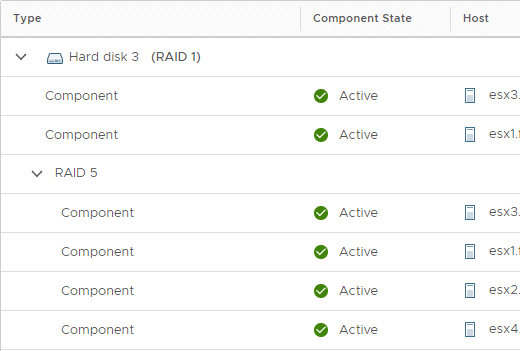
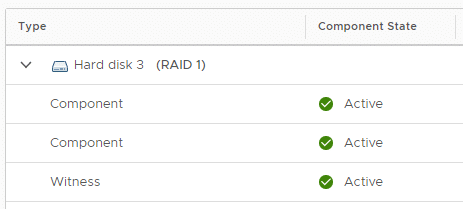
You can watch the transition progress in vCenter. The screenshot above shows the two mirrored components residing on ESX1 and ESX3, and the four new erasure coding components on ESX 1-4.
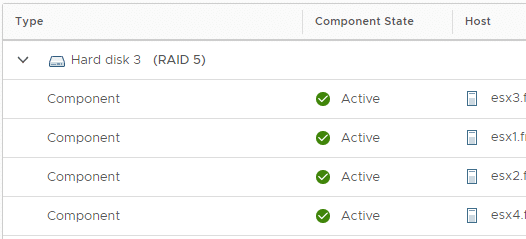
At the end of the policy transition the two mirrored components will be deleted and four components with 40 GB each will remain on the vSAN datastore.
Example with FFT=2
If you switch policy from RAID1 with FTT=2 to erasure coding with FTT=2 the phenomenon looks similar.
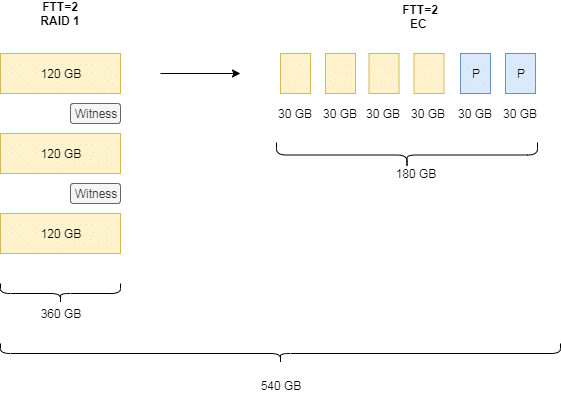
The example above shows a mirroring policy with two host failures to tolerate (FTT=2). Therefore vSAN has to place 3 copies on three different hosts. Additionally two witness components are required on two further hosts. Policy will be changed to erasure coding with FTT=2. Because erasure coding requires 2n+2 hosts we’ll get four data components and two parity components which vSAN has to distribute over six hosts. Temporarily the datastore requirement increases from 360 GB (3x 120 GB) up to 540 GB. At the end of transition it will drop to 180 GB.
Conclusion
I hope I could point out why vSAN needs slack space. Even if you have consumed all of your expected datastore, there needs to be some headroom for policy changes.