
Backup from Storage Snapshots – BfSS
The only reason to have BfSS enabled
BfSS can be described as an optional function available for primary backup jobs.
As you most likely know, every primary backup job needs to create a VMWARE snapshot on each virtual machine, before being able to back it up. This is needed for two reasons. First of all, to define and fix an exact point in time to be backed up. On top of that, as we back up running systems, we should be able to trigger application specific processes inside the VM before creation of the VMWARE snapshot. This allows to trigger VSS inside Windows workloads or take care of transaction log processing, quiescing, etc.
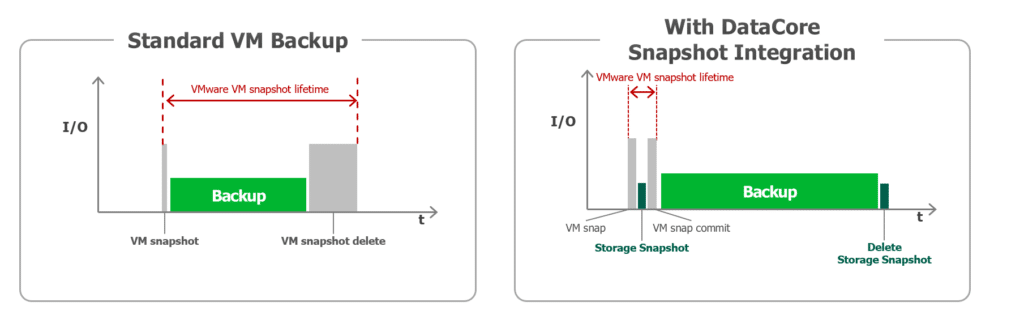
During the backup the VM continues to run and without BfSS every write access is forced to the delta file of the snapshot. As long as a VM does not generate a lot of change during its Veeam backup, this is totally fine. But for large VMs or VMs struggling with a lot of change to be written during a backup we could face issues. The delta files of a snapshot then can get large and committing the snapshot after the backup can thus take minutes or even hours. During this time we suffer reduced performance of the storage system due to the high IOPS generated by this “snapshot-commit”. In the worst case the VM will even suffer from so called stuns. That would be that the OS and the application inside stops working for some seconds. Users could be dropped out of their server applications. The network connectivity to the VM could be lost for some time.
BfSS is the solution to this scenario. Just by enabling it in the job settings, Veeam will trigger a snapshot inside the storage system using its own snapshot technology right after the VMWARE snapshot is present. With that the VMWARE snapshot with its defined state for the VM(s) is conserved for the backup. When the storage snapshot is there, we can right away commit the VMWARE snapshot as we do not need it any longer.
(Source: https://www.veeam.com/blog/datacore-sansymphony-plugin.html)
As the VMWARE snapshot had a much smaller lifetime in the BfSS case it can be committed way faster and without any trouble in most cases as it carries much less change than in the legacy case.
What makes storage snapshots superior to VMWARE snapshots for backups?
Why does it take much less time to get rid of a storage snapshot compared to a VMWARE snapshot? Even if it incorporates a lot of change?
The answer is that common enterprise storage systems in comparison to a VMWARE snapshot have an “inverted” snapshot method. With VMWARE’s method every change is written to a separate delta file that afterwards has to be merged costly back into the main data when the snapshot is deleted. Thus, we rather speak of a “commit” of the snapshot rather than a deletion. Storage systems in contrast do a “copy-on-first-write” on snapped LUNs. This means they always write directly into the main dataset but copy the old state of a block into a change buffer in advance of overwriting it. Deletion of a snapshot now only means discarding the change buffer. The main dataset already contains the most recent version. No commit is taking place – the snapshot gets indeed just deleted.
Automatic mount of the DataCore snapshot(s) to the Veeam proxy
There is also a major difference in respect to the proxy being used for the backup. When you do legacy (non-BfSS) Direct-Storage-Access backups with your proxies already, no matter if FC or iSCSI is used, you have to mount your productive LUNs to your proxies beforehand. Your Veeam proxy has to “see” the LUNs all the time to be able to fetch the data of the VMs during the backup.
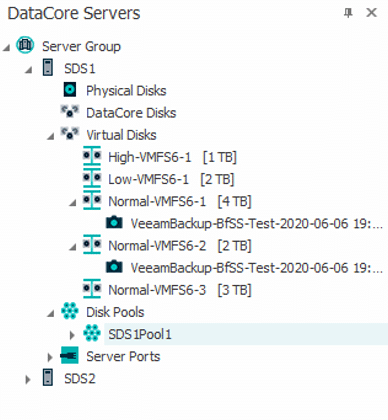
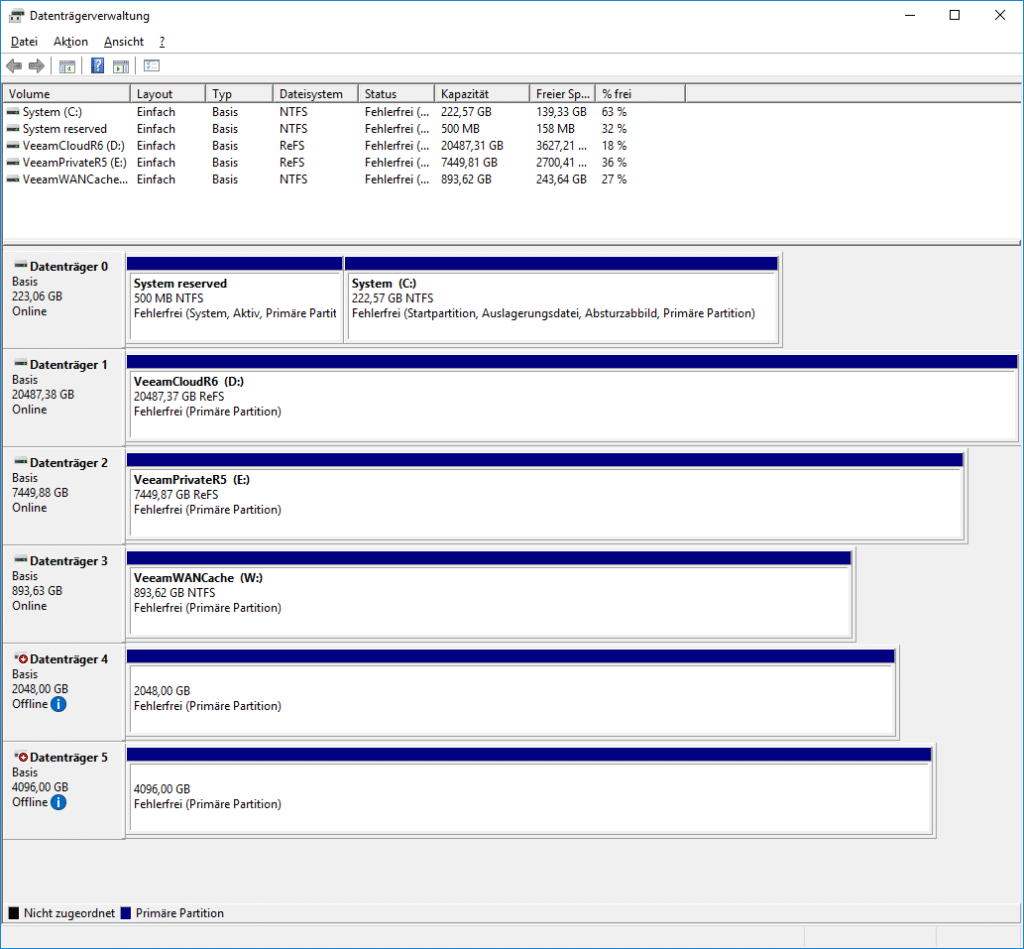
In case of BfSS, we are no longer fetching data from the productive VMFS LUNs. Rather we have to gain access to the storage snapshot that has been generated specifically for the backup and was not there before. So, in this case Veeam has to take care of mounting this snapshot to the proxy as well as unmounting it after the backup finishes and before the storage snapshot can be deleted. Therefore, the disk management of your Windows proxy server only shows additional “unknown” VMFS LUNs during a backup and not all the time. You still have to make sure of course, that a mount of a snapshot is generally possible though. FC connections and zoning for instance has to be appropriate in advance.
Activate BfSS and tune the options per job
BfSS is enabled by a single checkbox in the “Integration” menu of the jobs advanced storage settings.
Two additional options can fine tune the process further. Let’s dig into the details behind these options.
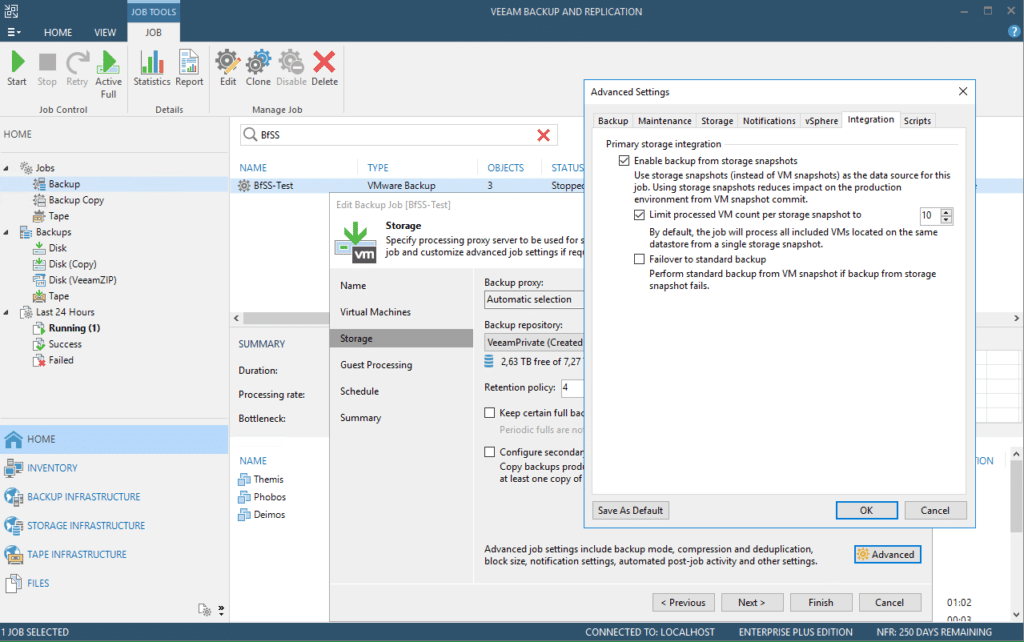
As a storage snapshot in contrast to a VMWARE snapshot carries not just a single VM but always all the VMs that have a footprint on the snapped LUN. Thus, we can and should include more than a single VM in each storage snapshot to speed up the whole process. It is though not advisable to have too many VMs with a VMWARE snapshot at the same time. Therefore, we can limit the number of VMs that will be backed up with a single storage snapshot. If you have more VMs in the job than the selected count, Veeam will add the selected count of VMs to a single storage snapshot. After these VMs are fully backed up the storage snapshot will be deleted and the next bunch of VMs will be VMWARE snapped in their group for the next storage snapshot.
The only pecularity you will see in the outcome is, that the point in time of the backup aka VMWARE snapshot will be very close together for a bunch of VMs and then there will be a gap to the next bunch.
With “Failover to standard backup” you can instruct Veeam to still back up the VMs in the job, even if the storage snapshot process fails or the LUNs does not get mounted properly. This failover could still be a Direct-Storage-Access backup – just without BfSS – if you have the productive LUNs constantly mapped to the proxy as well. Otherwise you would fall back to another mode (Hot-Add or NBD) with probably a negative impact on the backup performance.
Why BfSS is never faster and not always better than direct storage access alone,
but why I still love it
A common misconception regarding BfSS is, that the backup could be faster than with Direct-Storage-Access. This is not the case as the data path is the same in both cases. The only difference is the shorter lifetime of the VMWARE snapshot and the smaller impact on your production workloads. Your backup windows will stay the same.
Jobs with lots of small VMs with very few changes could though see a negative impact on the total runtime. The grouping together of VMWARE snapshots and the additional storage snapshot brings additional overhead that can only be justified for certain workloads. In my experience an average customer might end up with around 10% of the workloads in BfSS jobs while the rest might stay in legacy Direct-Storage-Access jobs.
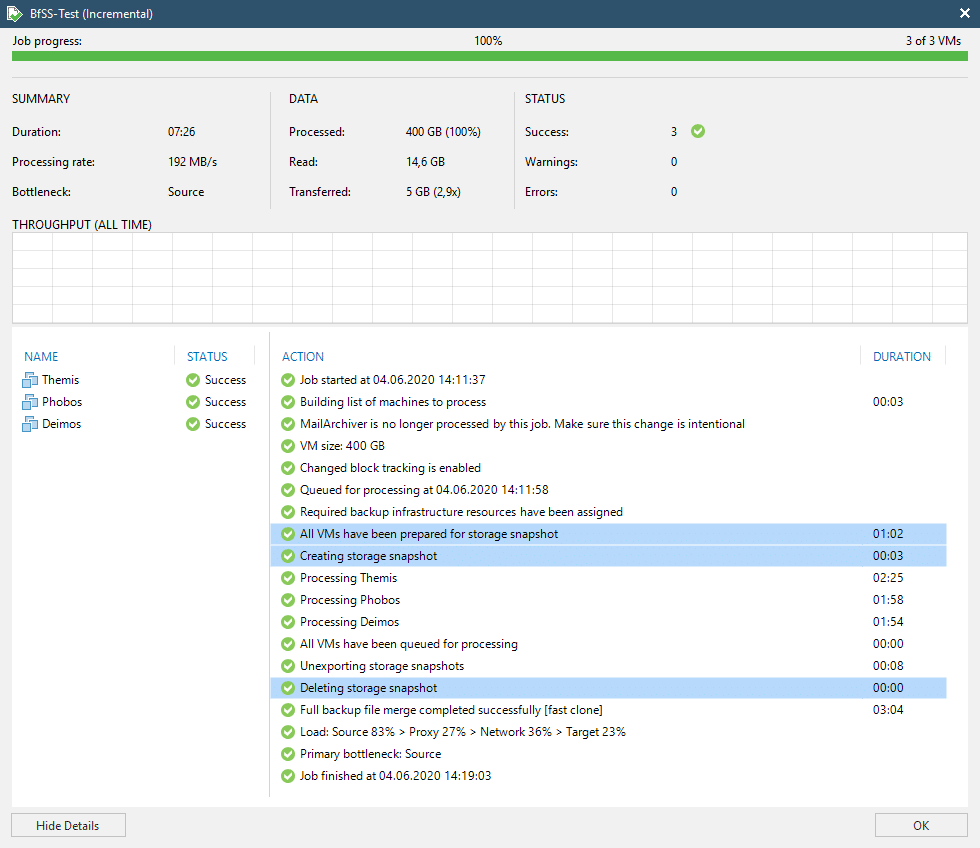
In the example shown in the screenshots you can see three VMs being backed up together in a single storage snapshot.
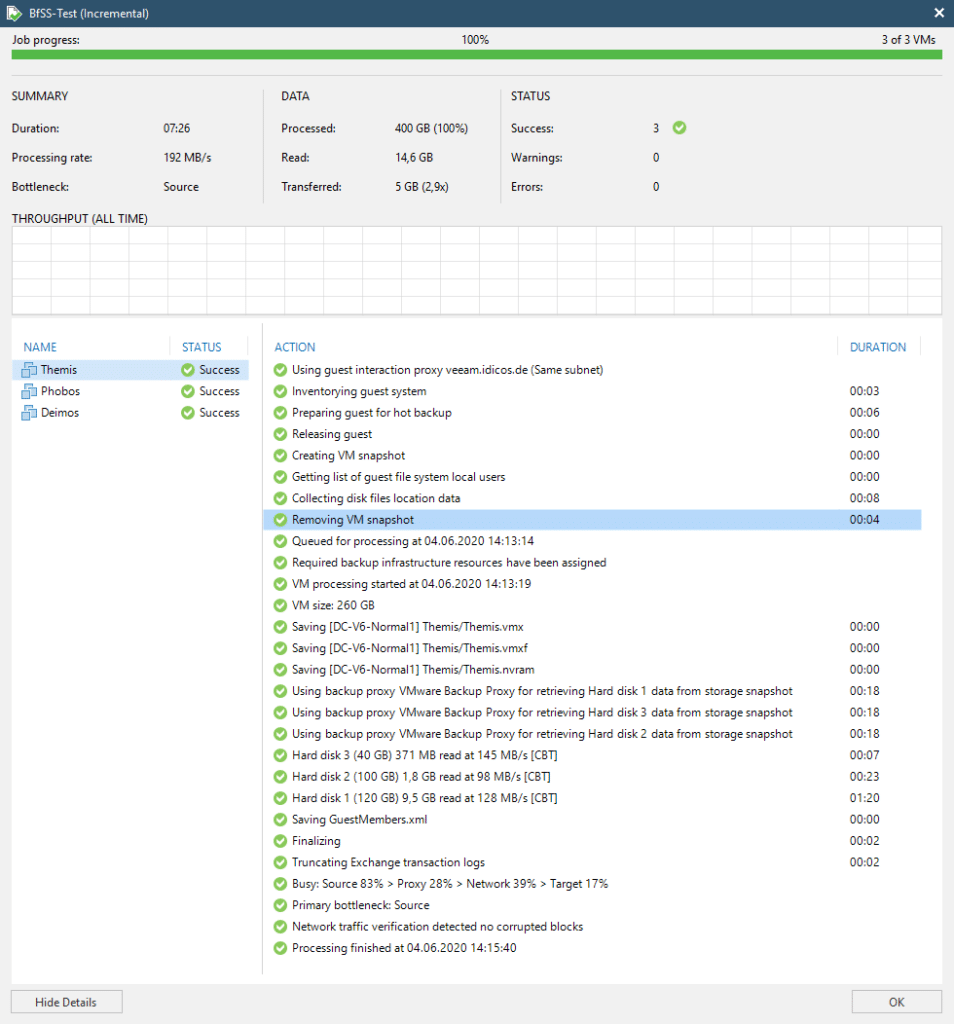
Many VMs in a single storage snapshot
Before the storage snapshot is created, each VM has to be fixed with a VMWARE snapshot individually. When all three have their snapshot ready, the storage snapshot takes place and the VMWARE snapshots are committed right away again. Lifetime of the VMWARE snapshot in our example is for server “Themis”, a Microsoft Exchange server, just 8 seconds. The commit of the snapshot takes only 4 seconds. No impact to users should be expected here.
Without BfSS the same system suffers from snapshot commit times of around 60 seconds. I’ve seen snapshot commit times after a regular Veeam backup of very large and active Exchange database servers with more than 2,000 users of up to 10 minutes. Those would benefit largely from BfSS.
Hi All,
Good News on the way, Datacore PSP14 will come soon and will give new features through CDP. Thanks to this update Veeam will be able to directly access the Datacore CDP. No more need Datacore Snapshot. Big Data economy and big flexybility.
Veeam normaly will update VBR just after and thats’it. We’ll all be able to recover a VM or guest files from reading Datacore CDP in point in time. (depending on how much you allocated to DC CDP for sure)
Hi Loïc.
Thanks for the update. To my knowledge it will even be uncoupled from PSP14 and is to be released as an updated plugin pretty soon.
An update to the blog post will follow. In general it will deliver the same outcome but the process will be much easier to handle.
Great news for DataCore users having a slight fear of ransomware (who does not?). 😉
Hi All,
which SAU size would you recommend for the snapshot pool?
If you use CDP, is there any advisory which SAU size should be used?
I read the Veeam digest from gostev. Veeam released the CDP feature in their updated Datacore plugin. I’m really looking forward to your blog post update.
Hi Alfred.
For a pure snapshot pool one might want to go as small as possible. I usually stick with 8 MB. 4 MB could also be an option. The smaller, the longer the pool can support your snapshots.
For CDP I did not find a best-practice recommendation. Through talks to DataCore SEs I narrowed my personal best-practice to 32MB as a trade off between overhead and granularity.