
Off-label usage
Using Veeam to recover from a DataCore CDP recovery point
A unique feature of DataCore is CDP or Continuous-Data-Protection. This feature can be enabled on each virtual disk (LUN) presented to your VMWARE cluster. CDP does not create any snapshots but constantly writes all changes into a rolling buffer.
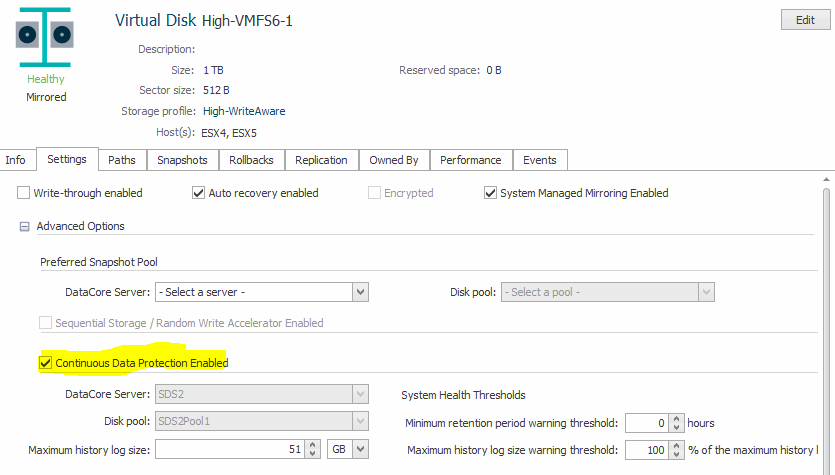
Depending on your DataCore license this buffer can be 2h, 8h or even more. The most recent licenses allow for up to 14 days of rolling buffer, provided you have enought space for a buffer of that scale. This allows for jumping to any historical point-in-time in this timeframe with the granularity of one second.
https://docs.datacore.com/SSV-WebHelp/Continuous_Data_Protection_(CDP).htm
Imagine a ransomware starts encrypting your fileserver and you restore to a point just a single second before the calamity hit. That allows for the best RPO one might think of.
Using just DataCore alone you might already roll a complete virtual disk with all its VMs back to an older state. But if you want it more granular from a VM or even file/object perspective – that’s when Veeam with the storage plugin in can come in handy. Unfortunately, the functionality didn’t make it into the Veeam console so far. This might be, because it is so special compared to all the other storage systems that use the same universal API.
Thus, we have to prepare it manually from the DataCore layer in the beginning. We will go through that process now step by step.
We first have to create a rollback in DataCore. This can be “expiring” or “persistent”. A persistent rollback will survive, even if it would fall out of the rolling buffer. The downside is: you will lose your productive LUN to conserve the rollback. This would be the choice if the ransomware left nothing but junk. With expiring the rollback will be dropped once it does not fit to the rolling buffer any longer. Thus, the productive LUN will be kept alive.
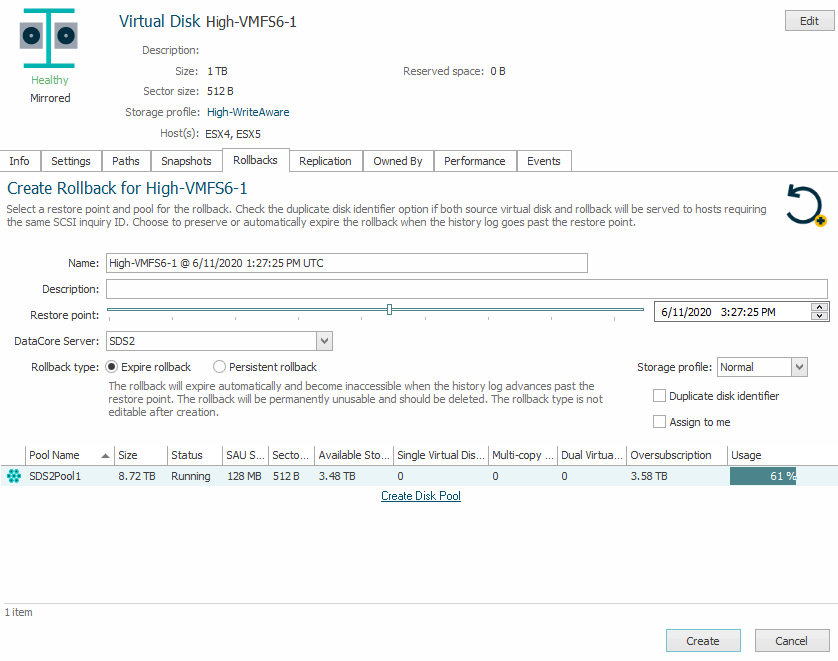
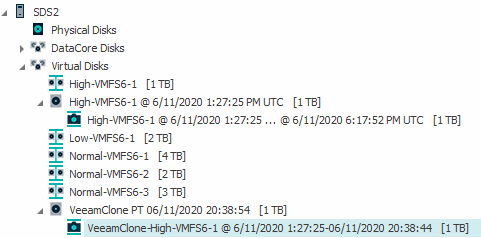
As the Veeam plugin does not look for a rollback, but only for snapshots, we have to do two more steps inside DataCore. First, we have to split the rollback into an independent disk.
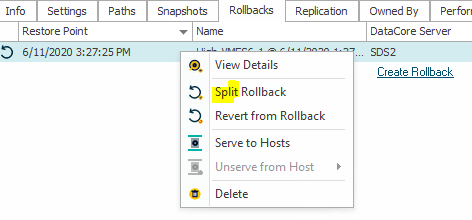
As data will now actually be copied into another volume, the process does take quite some time and consume additional space in your disk pool. If you plan to use this regularly; you should think of having an extra disk pool ready just for the split volumes. This will also speed up the process, as we can read and write to different aggregates now.

Once this process is finished, we’re not quite there. The clone is only a virtual disk right now. The Veeam plugin is trained on snapshots only. Therefore, we have to create a snapshot, though the LUN being static already.
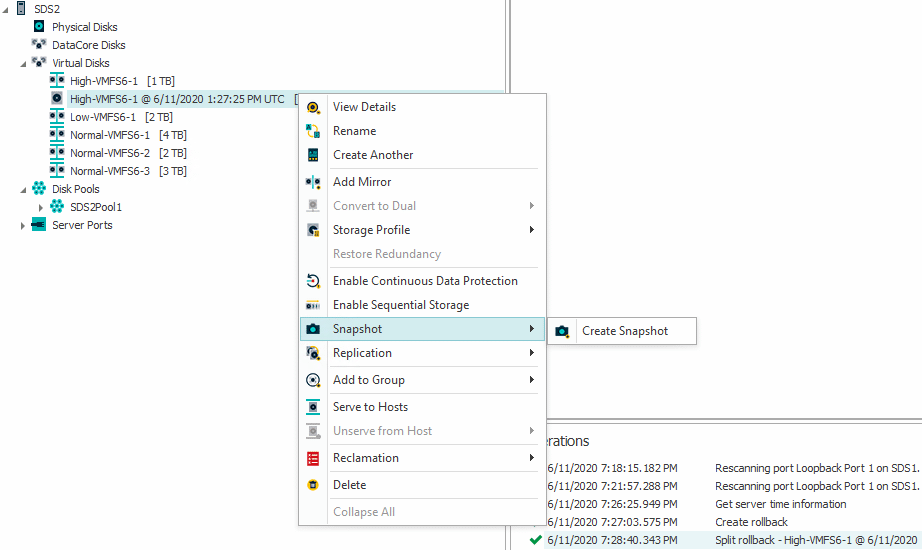
Keep it “differential” to minimize the space consumption.
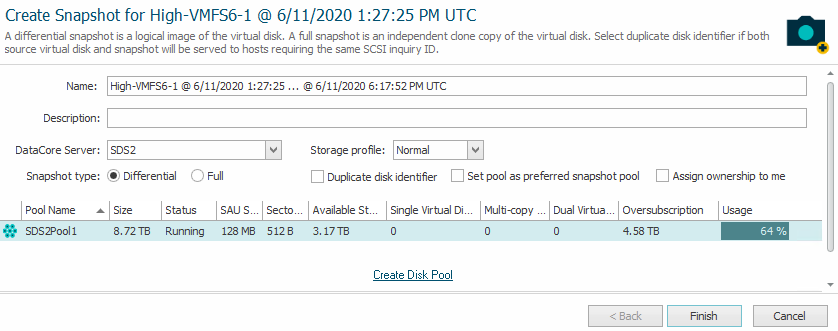
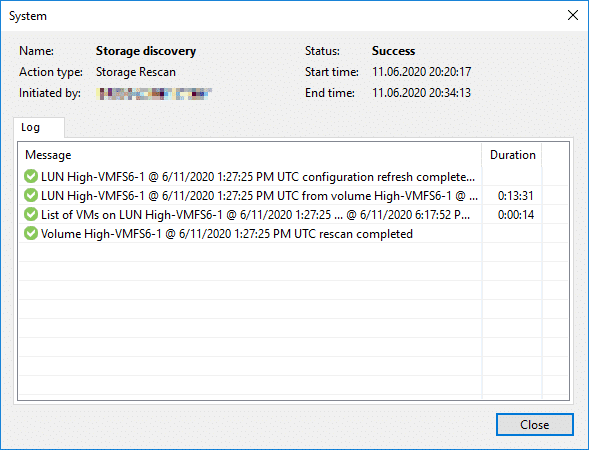
Once the snapshot is present, we can scan for snapshots in Veeam. As always, this can be somehow time consuming.
All the VMs inside the volume will be shown. Keep in mind, that this process by design provides crash-consistent restore points only.
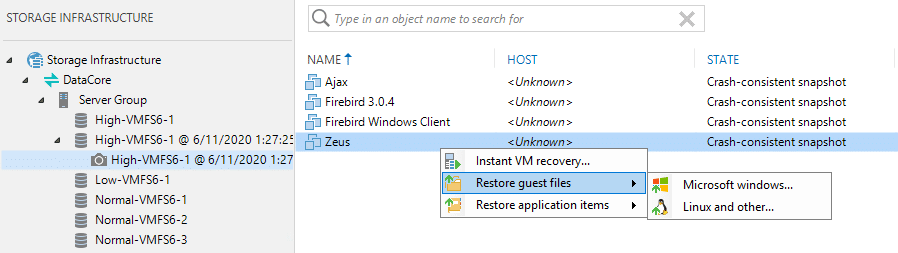
From this point on, all the options discussed on the preceding page are available for recovery. For all available recovery methods, the snapshot will be cloned and snapped again and the snapshot of the clone will be mounted to an ESX host, to get access to the VMs contents.
It sounds more complicated as it is. This workaround easily gives us access to an exact point in time without producing any snapshots or even backups in advance to the event.
Summary
The Veeam plugin discussed finally enables us to leverage all the nice functionality we’ve been waiting for together with DataCore SANsymphony. With CDP we even gain additional options to optimize our RPO further.
Hopefully DataCore together with Veeam will soon address the 1970 bug inside the plugin. Also one might think of integrating the CDP-trick into the console.
As we have quite some DataCore SB type licenses in place, I would personally wish for a fix for the capacity expansion limit you might run into, when doing recoveries.
Hi All,
Good News on the way, Datacore PSP14 will come soon and will give new features through CDP. Thanks to this update Veeam will be able to directly access the Datacore CDP. No more need Datacore Snapshot. Big Data economy and big flexybility.
Veeam normaly will update VBR just after and thats’it. We’ll all be able to recover a VM or guest files from reading Datacore CDP in point in time. (depending on how much you allocated to DC CDP for sure)
Hi Loïc.
Thanks for the update. To my knowledge it will even be uncoupled from PSP14 and is to be released as an updated plugin pretty soon.
An update to the blog post will follow. In general it will deliver the same outcome but the process will be much easier to handle.
Great news for DataCore users having a slight fear of ransomware (who does not?). 😉
Hi All,
which SAU size would you recommend for the snapshot pool?
If you use CDP, is there any advisory which SAU size should be used?
I read the Veeam digest from gostev. Veeam released the CDP feature in their updated Datacore plugin. I’m really looking forward to your blog post update.
Hi Alfred.
For a pure snapshot pool one might want to go as small as possible. I usually stick with 8 MB. 4 MB could also be an option. The smaller, the longer the pool can support your snapshots.
For CDP I did not find a best-practice recommendation. Through talks to DataCore SEs I narrowed my personal best-practice to 32MB as a trade off between overhead and granularity.